

最近的视觉-语言-动作 (VLA) 模型依赖于 2D 输入,缺乏与更广泛的 3D 物理世界领域的集成。此外,他们通过学习直接映射来执行动作预测

AI news tracing site



最近的视觉-语言-动作 (VLA) 模型依赖于 2D 输入,缺乏与更广泛的 3D 物理世界领域的集成。此外,他们通过学习直接映射来执行动作预测

Google也弄了一个:一张照片+音频即可生成会说话唱歌的视频的项目 VLOGGER:基于文本和音频驱动,从单张照片生成会说话的人类视频

速度最快最有性价比的型号 每百万输入token0.25美元,每百万输出token1.25美元。
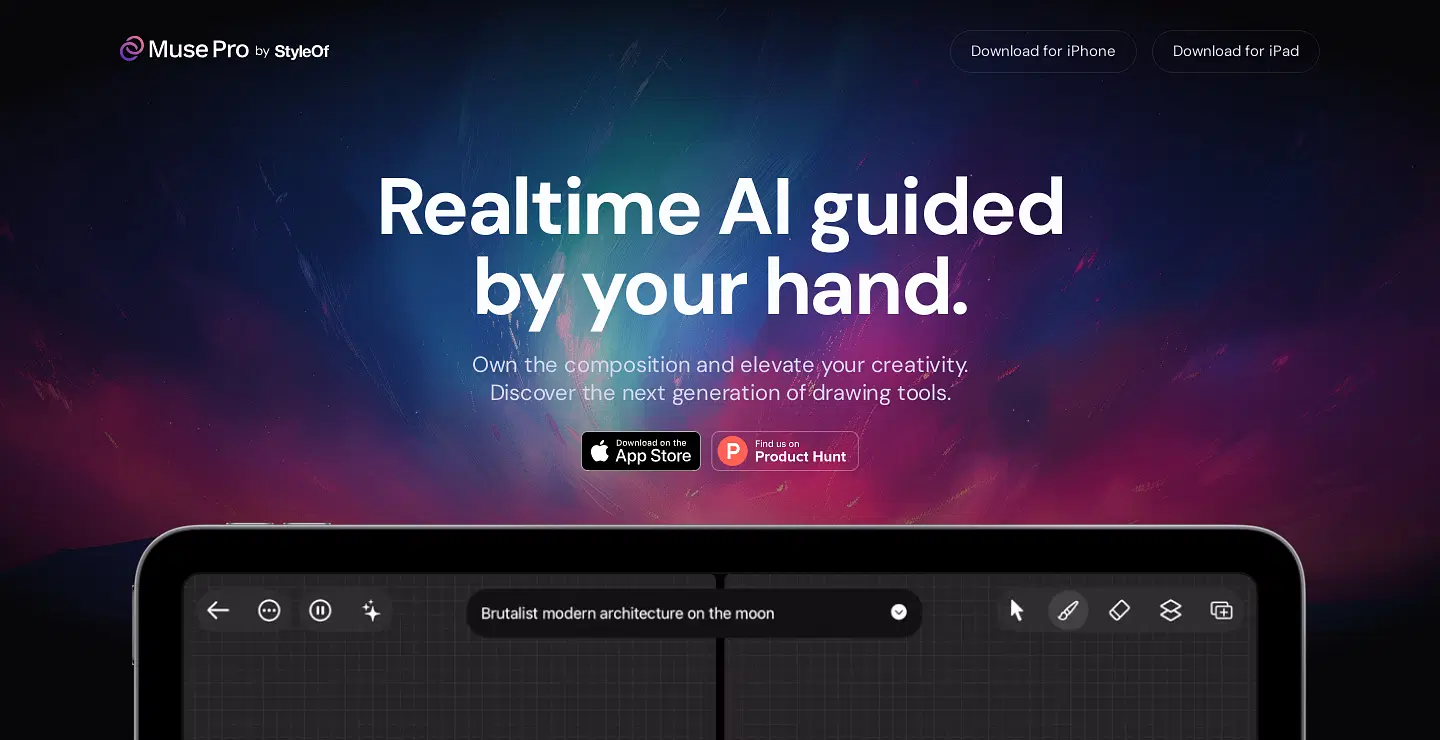
与其他画笔快速生成图片的尴尬应用不同,Musepro这个iPad 应用看起来是真的可用。借助 iPad 搭配的 Apple Pencil以及内置的丰富笔刷,应该可以极大的提高画图效率。

成本大约 $3,600,可以用来记录真人手指的动作来训练机器人进行灵活的操作。 并且不是遥控操作,它有一对特制的手套,通过各种传感器捕捉手部运动的精确数据。与传统基于视觉的运动捕捉技术相比,这些手套不会因为视线遮挡而失效,更适合在日常活动中使用。
通过提供一个将自然语言查询转化为 Selenium 代码的引擎,LaVague 可让用户或其他人工智能轻松实现自动化,轻松表达网络工作流程并在浏览器上执行。

Human to Humanoid (H2O)由卡内基梅隆大学的研究团队开发,它允许人们通过一个简单的RGB摄像头让机器人实时模仿人的全部动作。

→ 与大学合作提供AI课程。 → 你可以获得来自知名学府的证书。 → 课程种类齐全,适合初学者到专家级学习。

在你输入的指令后面加上 --cref URL,URL是你选择的角色图像的链接。 你还可以用 --cw 来调整参照的“强度”,范围从100到0。 默认的强度是100 (--cw 100),这时会参考人物的脸部、发型和衣着。 如果设置为强度0 (--cw...
@deepseek_ai 的视觉语言模型专为现实世界的视觉和语言理解应用程序而设计。

能够通过文字提示创造出适用于各种场景的声音和音效 如游戏中的射击和跳跃声音、动画中的雨声环境以及视频中的地铁到站声音等。
谷歌推出了关于生成AI的免费学习路径。 微软:AI生成对于每个人 哈佛的CS50人工智能入门课程(使用Python)

基于 Llama2,从头开始训练。 许可 - 开源。 优化在 CPU 上运行。 🔥 高度可控,可选择节奏、和弦进行、小节范围等等!
多语言、多口音、CPU 实时且完全免费。 它支持英语、西班牙语、法语、中文、日语和韩语。回顾一下开源历史上导致 Linux 诞生的重要时刻
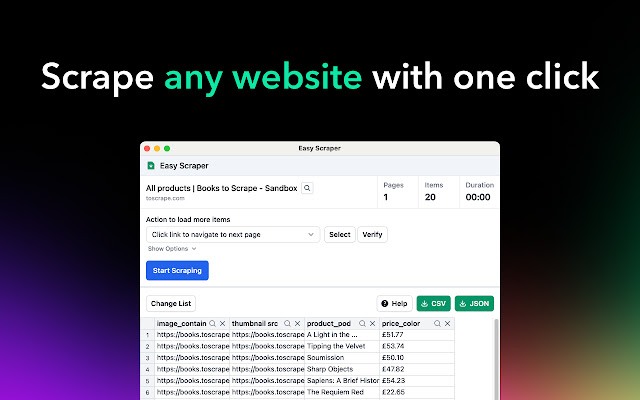
Easy Scraper:一个在Chrome扩展,只需点击一下即可抓取任何网站的内容 支持导出CSV或JSON格式可以直接丢到ChatGPT里面进行简单分析,也可以作为GPTs的知识库。 这个工具目前完全免费,原因是开发者将在整个三月份参加沉默冥想闭关,没有时间添加付费计划。
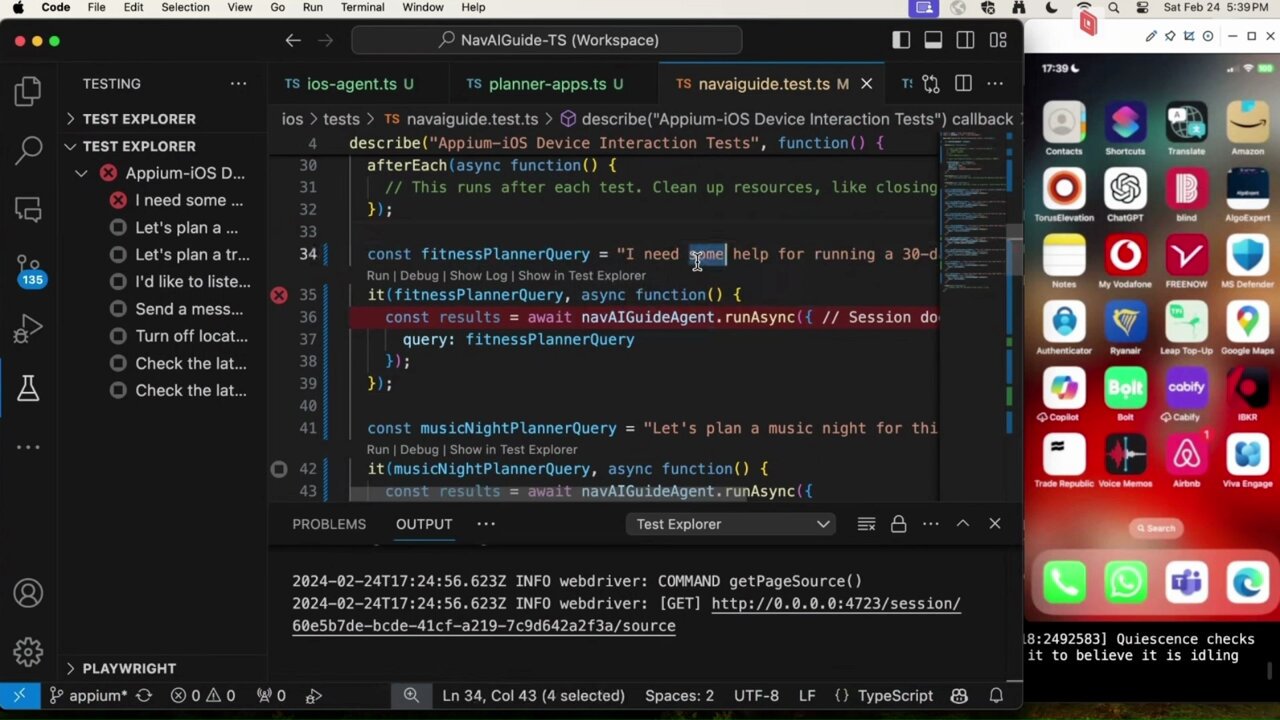
这证明了 GPT-4V 作为通用移动 AI 代理的出色程度 - 无需任何微调或基础,仅通过与启用 JSON 模式的文本模型集成即可。 建议观看此演示,了解(可能)令人惊叹的因素以及使用 NavAIGuide 在 iOS 17 上的结果, NavAIGuide 是 LLMs 的移动和 Web...








