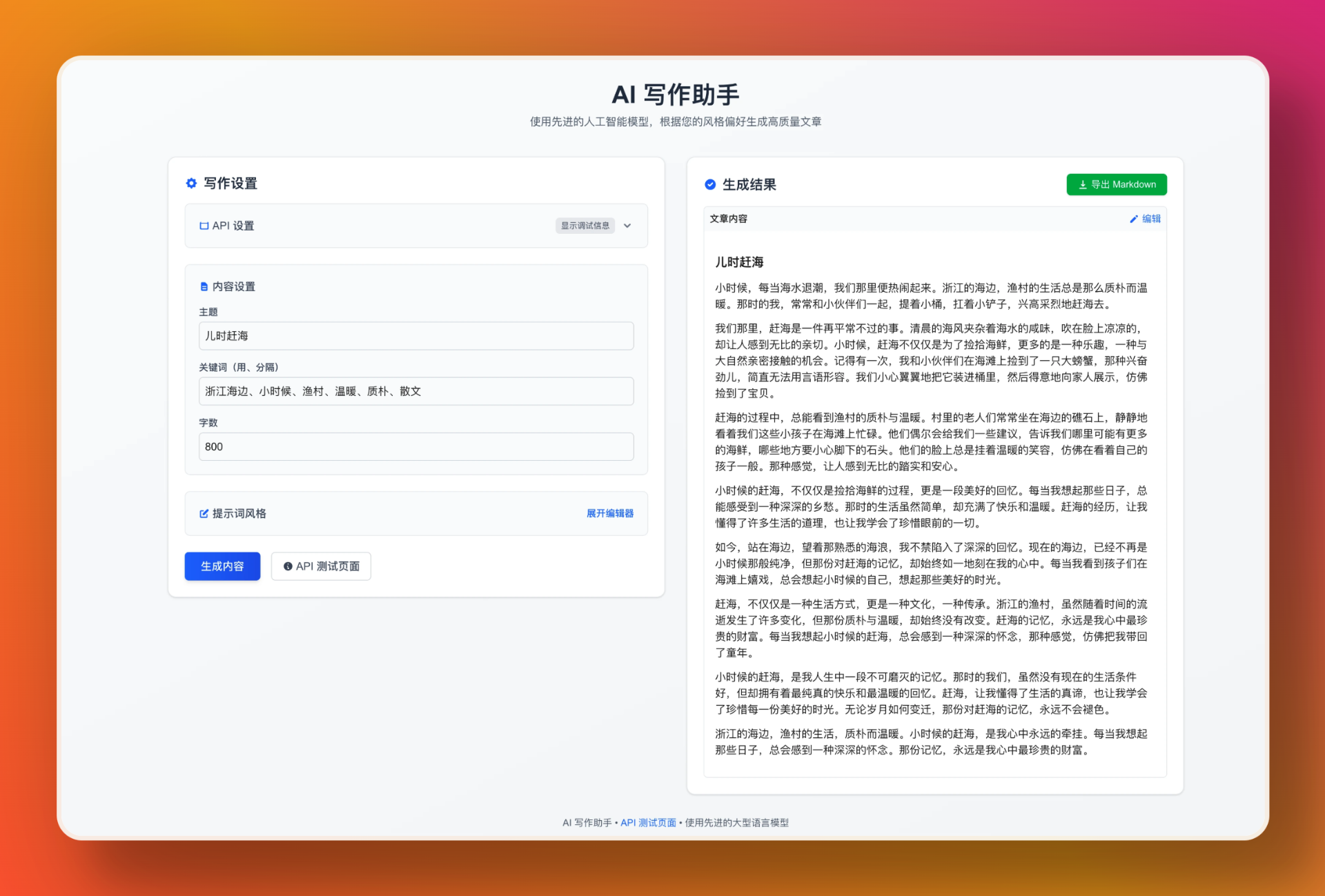
AI写作助手:多模型写作与AI痕迹优化工具
提供了智能内容生成、风格定制、AI 特征去除、检测对抗优化、Markdown 导出等功能,适合作家、学生、内容创作者等使用。
该项目是一个基于 Next.js 构建的开源 AI 写作助手,旨在帮助用户通过大型语言模型(LLM)生成高质量内容。

提供了智能内容生成、风格定制、AI 特征去除、检测对抗优化、Markdown 导出等功能,适合作家、学生、内容创作者等使用。
该项目是一个基于 Next.js 构建的开源 AI 写作助手,旨在帮助用户通过大型语言模型(LLM)生成高质量内容。

一个高效的开源视觉语言模型,提供强大的图像理解能力,同时具有极小的资源占用。
提供了两个模型变体:Moondream 2B,拥有20亿参数,适用于一般图像理解任务,如图像描述、视觉问答和物体检测。
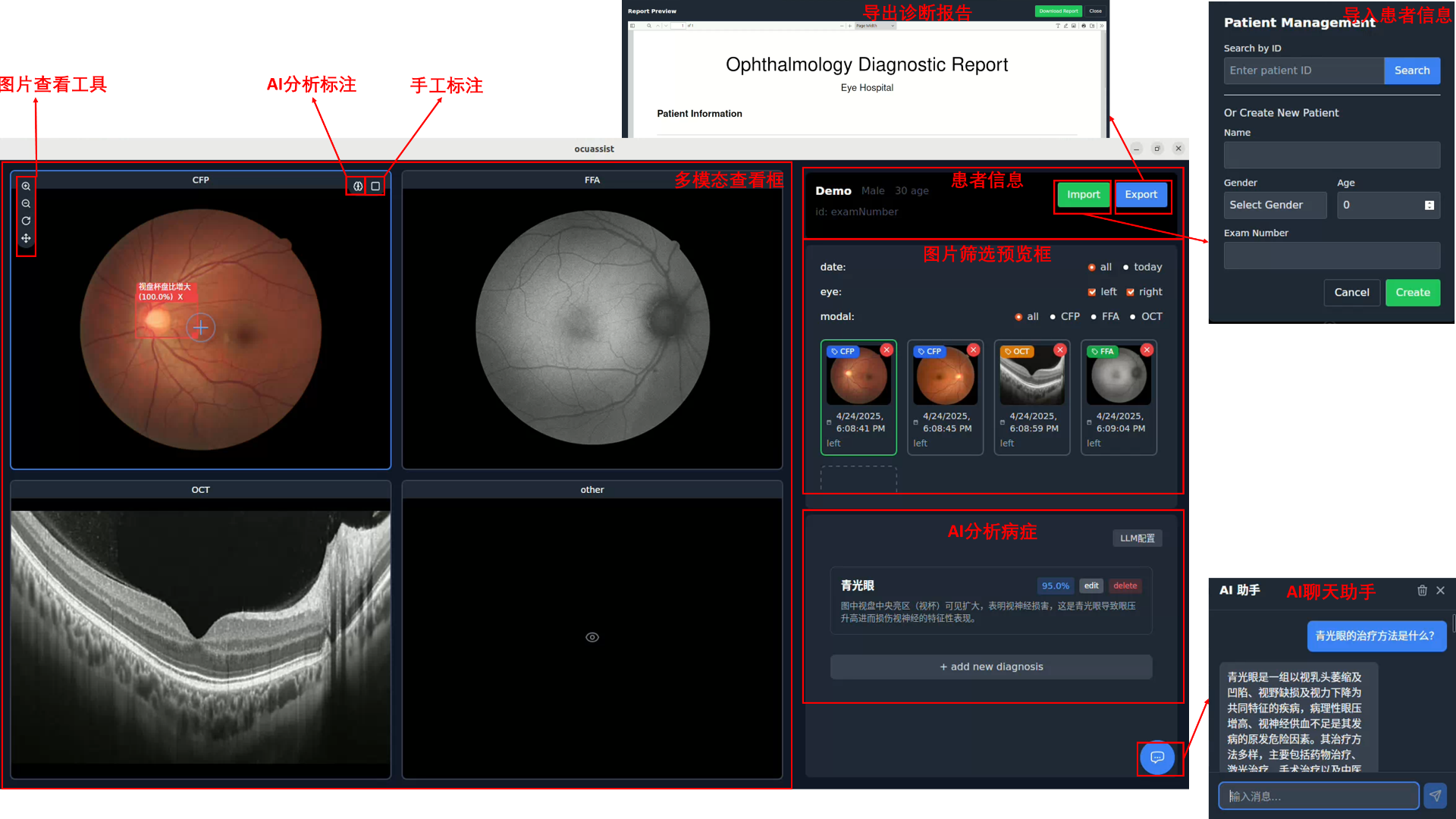
OcuAssist 是一个开源的 AI 辅助眼底多模态诊断软件,旨在为眼科医生提供智能化的诊断支持。 该项目由 GitHub 用户 ji2814 开发,基于 Tauri 框架构建,结合了前端和后端的多种现代技术。

一个关于无限画布的教程,帮助开发者理解和实现无限画布的概念与功能。
无限画布是一种允许用户以非线性方式自由组织内容的界面,支持缩放、直观编辑基本图形(如移动、分组和修改样式)等功能。”
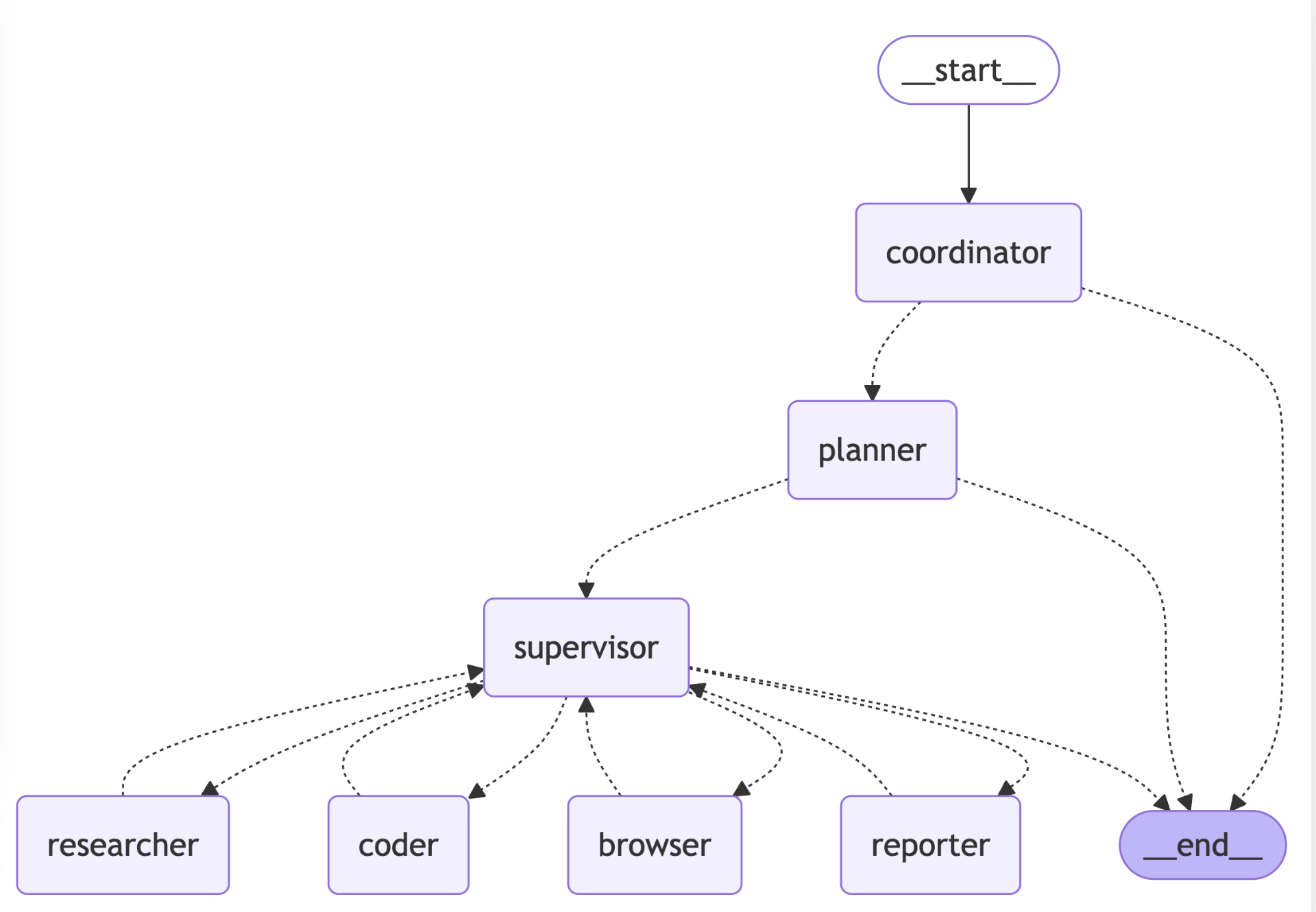
LangManus 是一个社区驱动的 AI 自动化框架,旨在将语言模型与专业工具(如网页搜索、爬虫和 Python 代码执行)相结合,以实现复杂任务的自动化处理。
用于为原生 Ollama 服务添加 API 密钥认证功能。该项目解决了 Ollama 官方不提供 API 密钥验证的问题,使您可以更安全地部署 Ollama 服务并防止未授权访问。

经常做自媒体的小伙伴们,水印移除一直是图片处理的难题,最近发现一款完全开源免费的 AI 水印移除工具:WatermarkRemover-AI。
一个基于 Python 的轻量级框架,它的目标是帮助开发者更方便地调用和组织大型语言模型(如 ChatGPT、Claude、Gemini)的多步骤推理过程 —— 简单来说,就是构建“多轮对话”或“任务链”变得前所未有的清晰、模块化。
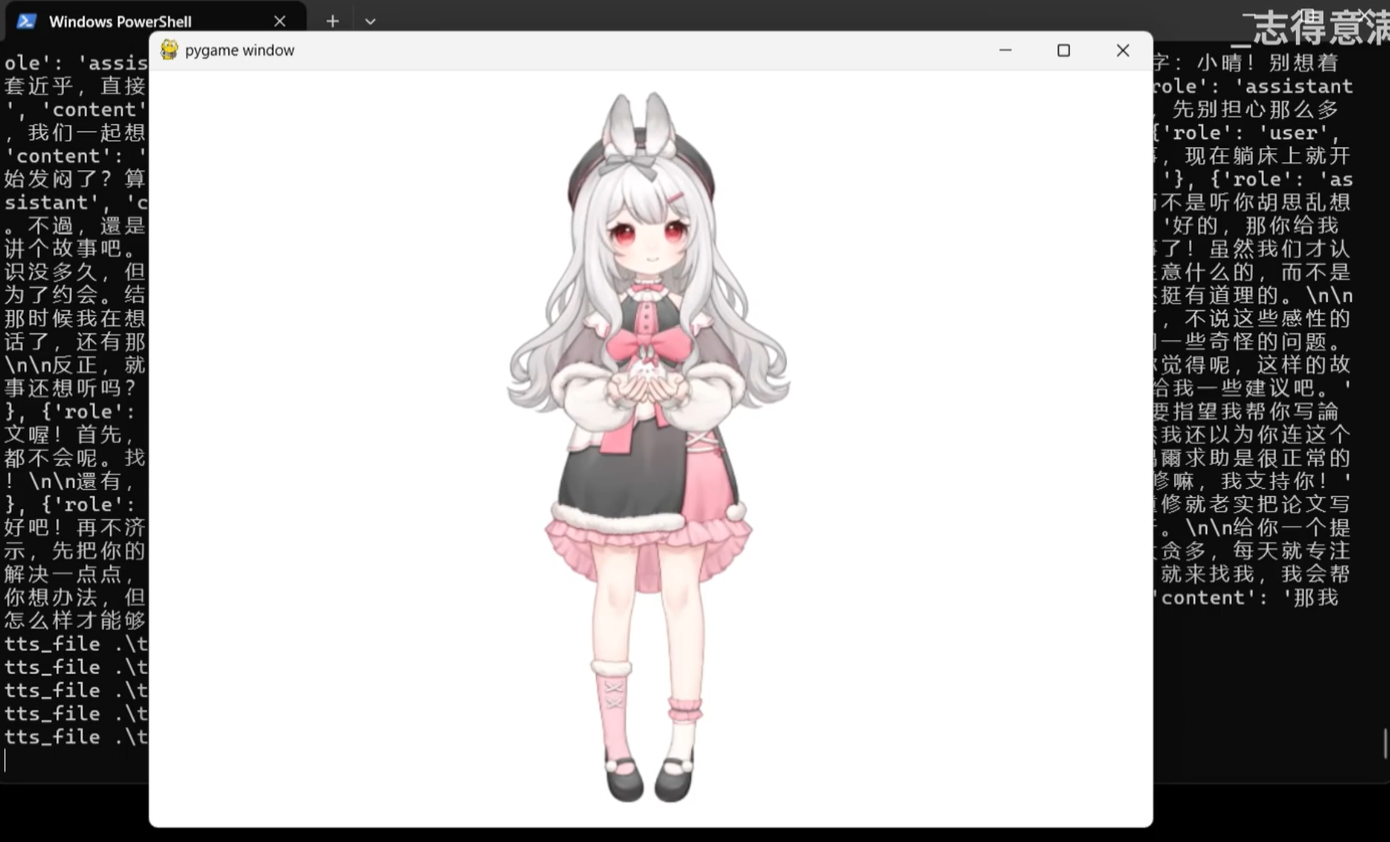
EdgePersona 是一个开源项目,旨在创建一个完全本地化运行的智能数字人系统。该系统设计轻量高效,对硬件要求低,适合在普通笔记本电脑上运行,保障用户隐私。

WeClone 是一个开源项目,旨在通过微信聊天记录微调大型语言模型(LLM),实现个性化的数字分身,并可部署为微信、QQ、Telegram 等平台的聊天机器人。