
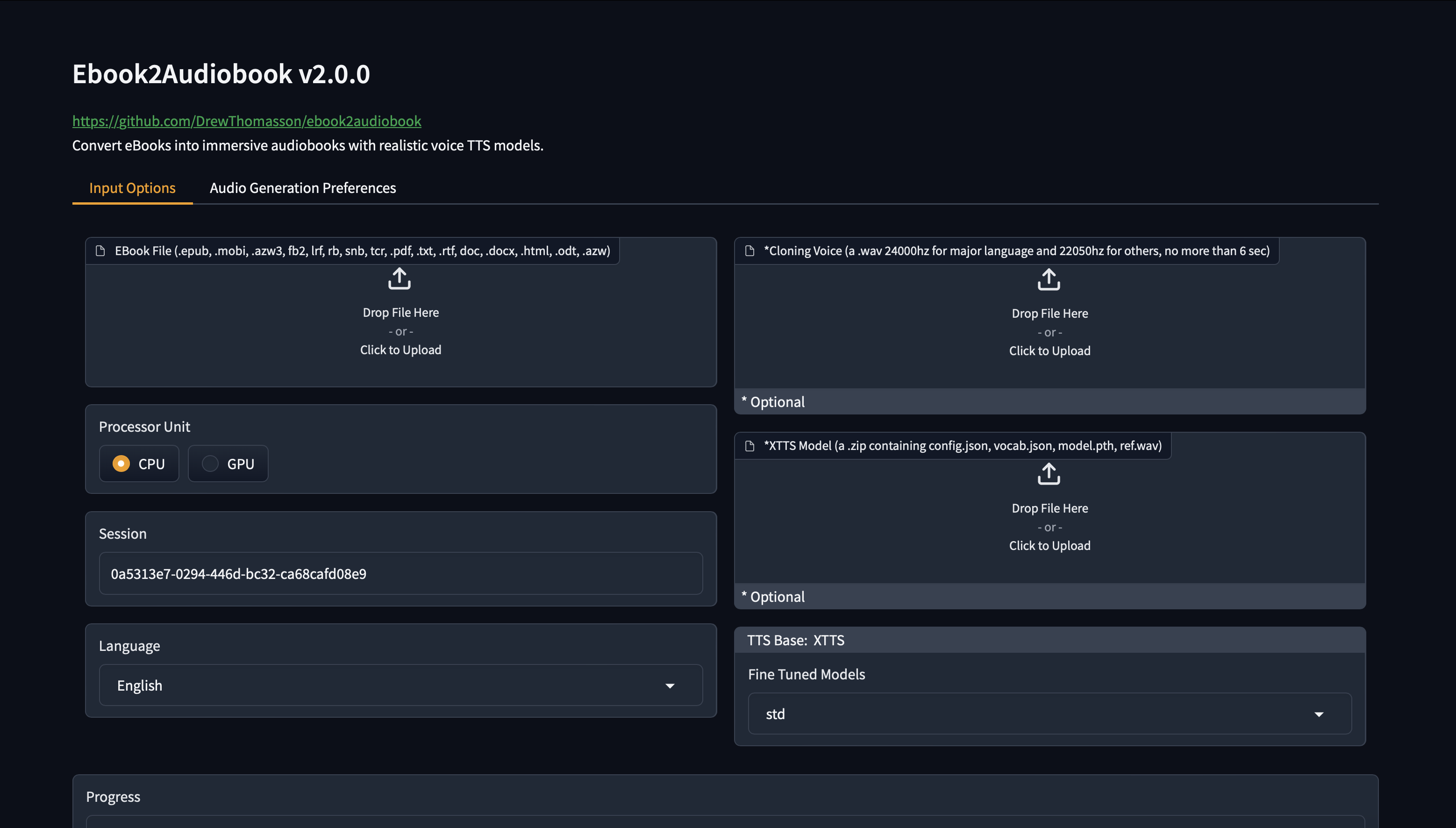
Ebook2Audiobook开源项目
将电子书自动转换为有声书 支持语音克隆、多种语言
ebook2audiobookXTTS 是一个开源项目,旨在将电子书自动转换为有声书,并支持多种语言、语音克隆和章节信息的生成。该项目结合了 Calibre(电子书转换工具)和 Coqui XTTS(文本转语音引擎),通过简单的命令或Web界面完成转换
将电子书自动转换为有声书 支持语音克隆、多种语言
ebook2audiobookXTTS 是一个开源项目,旨在将电子书自动转换为有声书,并支持多种语言、语音克隆和章节信息的生成。该项目结合了 Calibre(电子书转换工具)和 Coqui XTTS(文本转语音引擎),通过简单的命令或Web界面完成转换
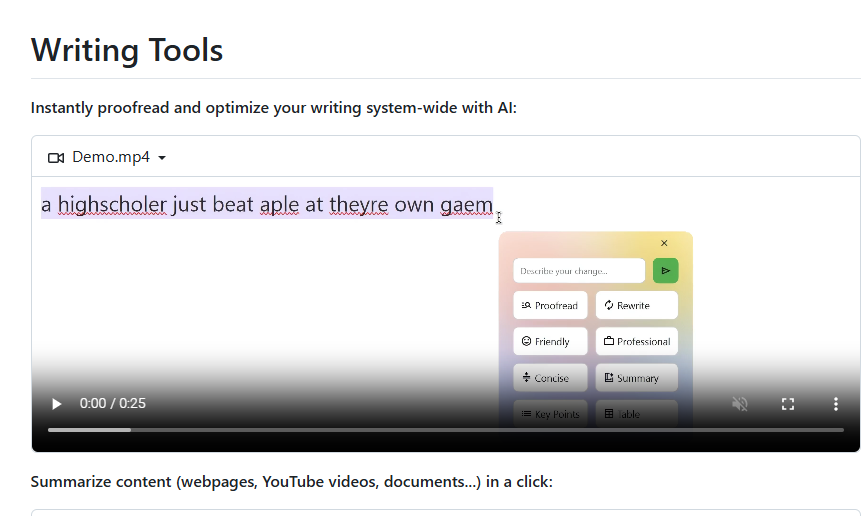
一款名为Writing Tools的开源应用为Windows 11用户带来了类似Apple Intelligence的写作工具功能。该应用支持与多种大型语言模型(LLM)连接,包括Gemini、OpenAI等,提供翻译、摘要、校对等多项功能。用户只需简单配置,即可在Windows系统上无缝使用这些高级写作辅助工具
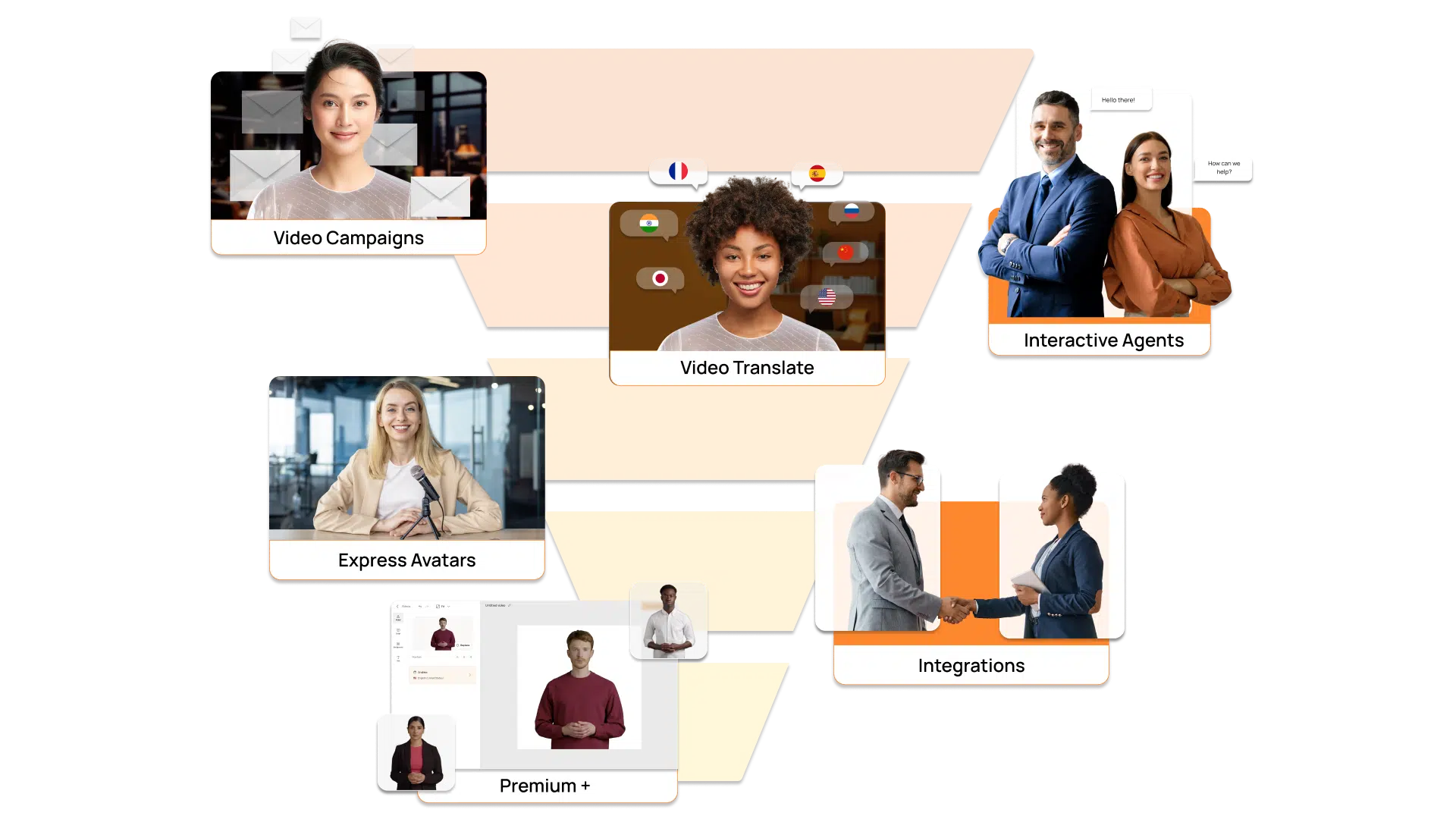
AI视频平台D-ID推出了两款新型数字人工具—Express和Premium+,专为内容创作设计,旨在让企业在市场营销、销售和客户支持等领域应用更逼真的虚拟人。Express虚拟人只需一分钟视频训练即可生成,能够同步用户头部的运动;而Premium+虚拟人需要更长的视频进行训练

可控人物影像產生旨在產生以參考影像為條件的人物影像,從而允許精確控制人物的外觀或姿勢。然而,現有方法儘管實現了較高的整體影像質量,但通常會扭曲參考影像的細粒度紋理細節。我們將這些扭曲歸因於對參考影像中相應區域的關注不夠
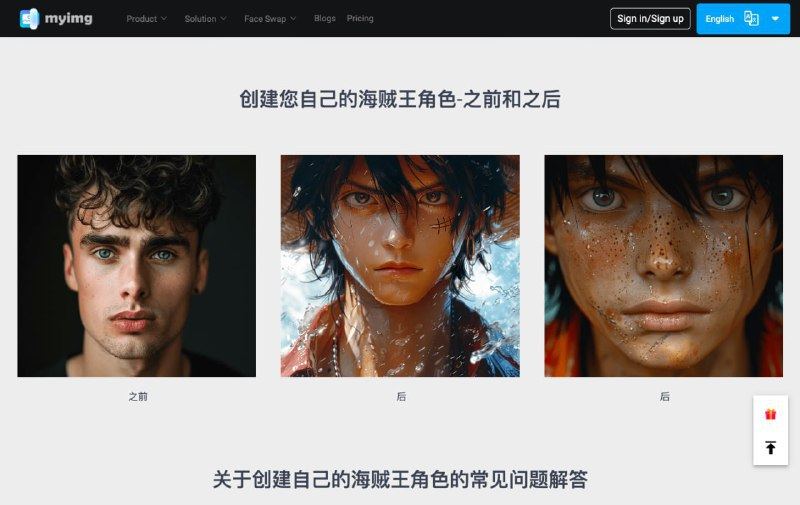
网站简介:一款可以将照片即时转换为卡通和动画艺术风格的人工智能工具。
只需上传一张照片,网站的AI技术会迅速将其转换为一个个性化的《海贼王》动漫角色。

支持在移动设备上实时运行的超轻量级数字人模型
Ultralight-Digital-Human 是一个创新的开源项目,使得数字人在移动设备上的实时应用成为可能,旨在实现超轻量级的数字人模型,其能够在移动设备上实时运行。
支持在移动设备上实时运行的超轻量级数字人模型
提供了详细的训练和推理步骤
现代计算设备功能强大且小巧,可以轻松佩戴在身体上。然而,电池成为设计和用户体验的主要障碍,增加了设备的重量和体积,并且需要定期充电和移除设备。
为了解决这些问题,卡内基梅隆大学的研究人员提出了通过人体传输能量的“皮肤供电”技术。
強大的計算設備現在足夠小,可以輕鬆佩戴在身上。然而,電池造成了主要的設計和使用者體驗障礙
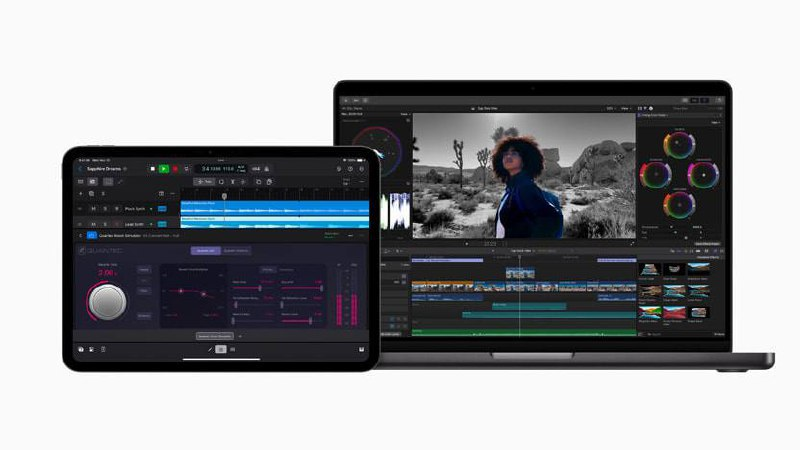
Ebook2Audiobook开源项目
将电子书自动转换为有声书 支持语音克隆、多种语言
Hertz-dev:首个会话音频开源模型
小宾AI抠图
AI 头像动起来
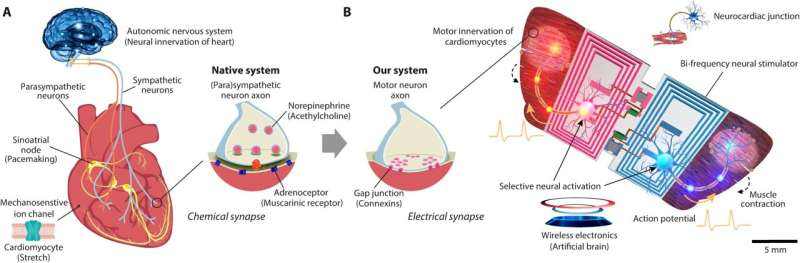
來自美國布萊根婦女醫院和瑞士 iPrint 研究所的生物研究人員和機器人專家組成的聯合團隊,利用人類運動神經元和心肌細胞來模擬肌肉組織,開發了微型游泳機器人。
他們的論文發表在《科學機器人》雜誌。科羅拉多大學博爾德分校的機械工程師Nicole Xu 在同一期期刊上發表了一篇焦點文章

長谷川-約翰遜領導了“語音無障礙項目”,這是伊利諾伊大學厄巴納-香檳分校的一項舉措,旨在使語音識別設備對有語言障礙的人更有用。
在該計畫第一份發表的研究中,研究人員要求自動語音辨識器聆聽帕金森氏症相關言語障礙患者長達 151 小時(幾乎六天半)的錄音。

一项探索该技术如何降低灾害风险的新研究表明,人工智能可以在半小时内预测煤矿中与瓦斯相关的事件。
这项针对中国煤矿的研究比较了 10 种机器学习算法,看看哪种人工智能方法可以提前 30 分钟预测甲烷气体含量的变化,并通知用户异常情况。 《气体预警系统短期预测十种机器学习算法的比较研究》发表在《科学报告》杂志上。










