Web应用程序:支持文本到图像和图像到文本的转换
网站功能:AI 图像生成
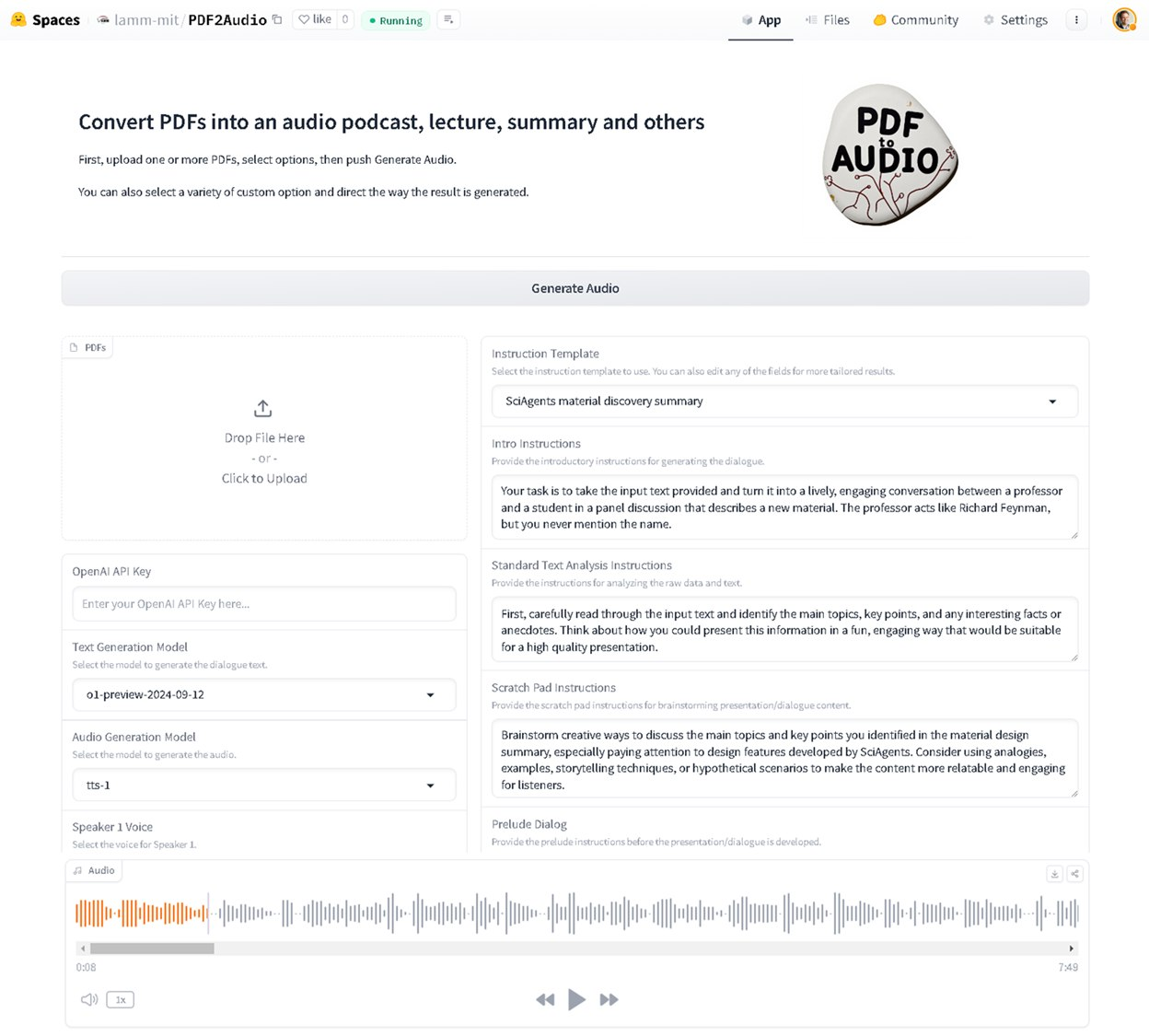
网站名称:PainterLeaf
网站简介:一个免费的Web应用程序,支持文本到图像和图像到文本的转换。
支持多种模型,包括Flux.1和StableDiffusion 3.5,可以通过输入文本生成图像,或将本地图像转换为文本提示。
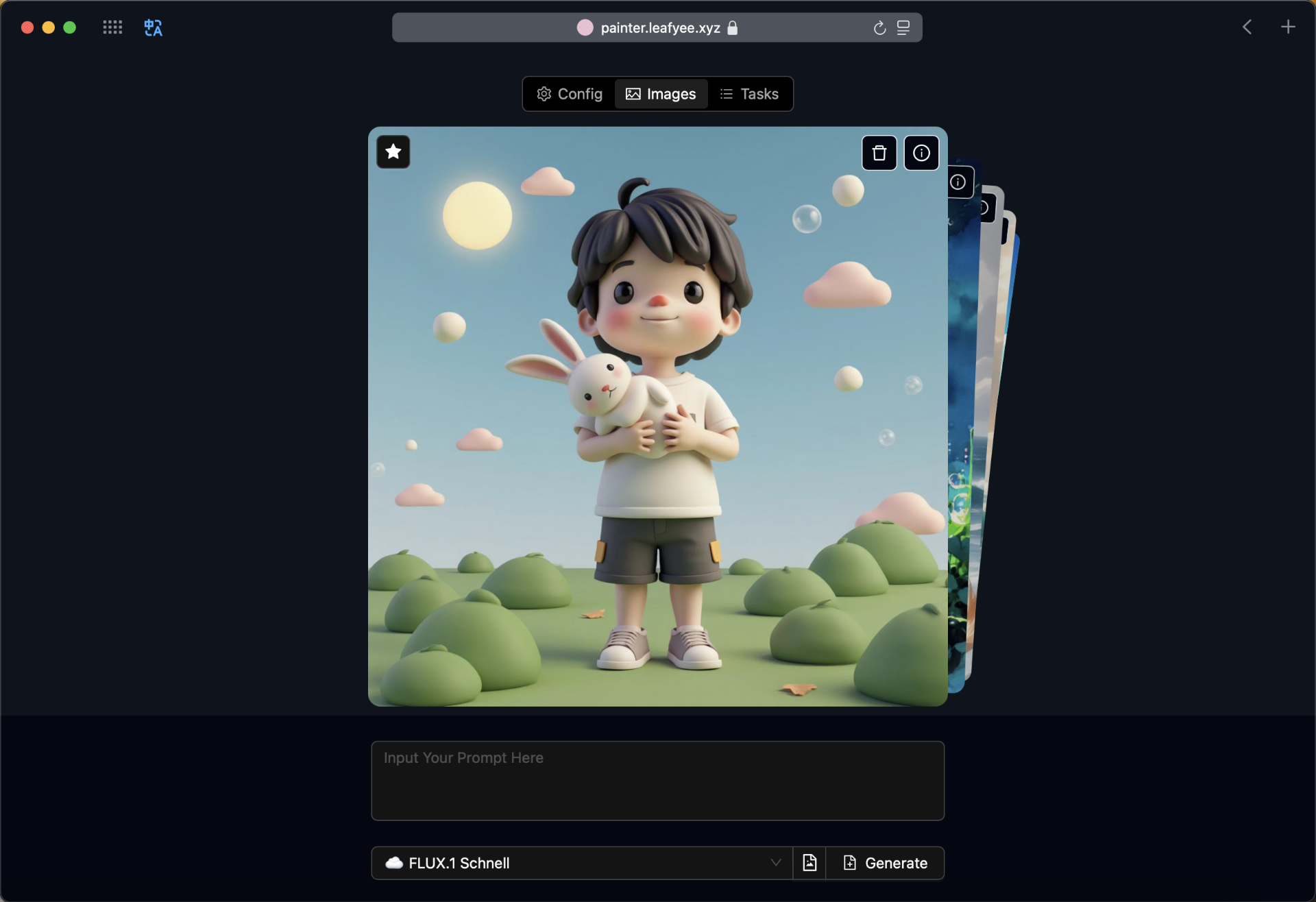
网站功能:AI 图像生成
网站名称:PainterLeaf
网站简介:一个免费的Web应用程序,支持文本到图像和图像到文本的转换。
支持多种模型,包括Flux.1和StableDiffusion 3.5,可以通过输入文本生成图像,或将本地图像转换为文本提示。
使用扩散技术生成完整的三分钟以上歌曲
简介:FUZZ 是 Riffusion 推出的最新音乐生成模型,利用扩散模型生成音乐谱图,并转换为音轨可供下载。尽管目前中文语言能力有待提高,但 FUZZ 的功能与 Suno V2 相当,且承诺在 GPU 资源允许的情况下保持免费。
音乐风格:支持多种音乐风格,助力创作多样化的音乐作品。
网站功能:AI 视频生成
网站简介:一个专注于AI视频生成的社区平台,通过用户生成的视频、教程和博客,激发创作者的灵感。
可以利用MiniMax AI的强大功能,将文本和图像转换为动态视频,快速生成高质量的视觉内容。
大語言模型(LLMs )和多模型模型已成為改變遊戲規則的人
ElevenLabs 发布了一个开源的小项目,X-to-Voice ,允许用户通过分析 Twitter 资料生成自定义的声音和头像。这个项目使用了 ElevenLabs 的新声音设计 API 和 Taedra 动态头像生成工具。
用户可以输入 Twitter 账号名称,系统将分析其资料数据生成特有的语音和动画头像。
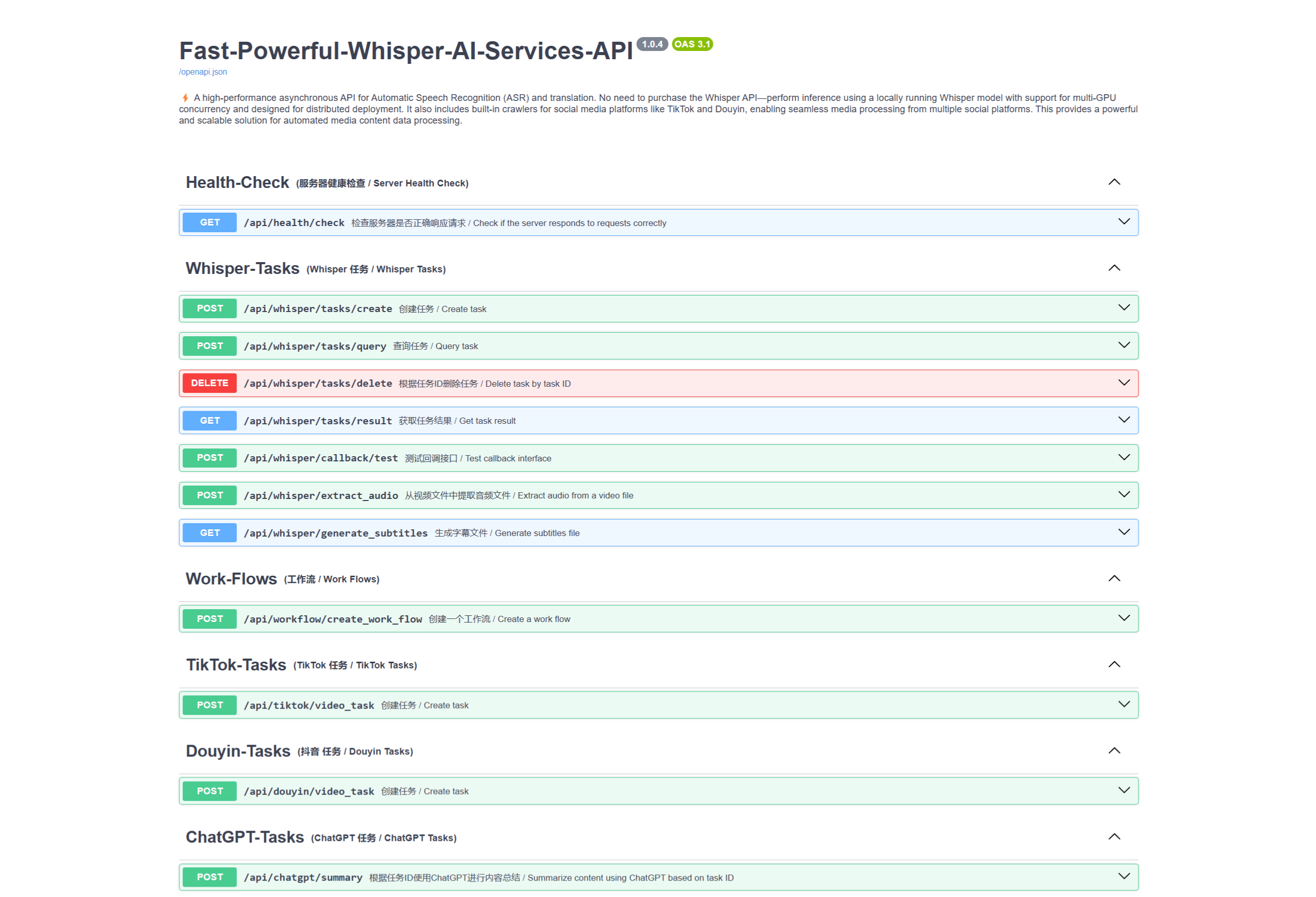
该项目基于 OpenAI 的 Whisper 模型,并利用 FastAPI 的异步特性对其进行高效包装,支持异步任务队列,文件处理,网络爬虫,以及更多自定义功能。
「Fast-Powerful-Whisper-AI-Services-API 」的愿景是打造一个强大且开箱即用的 Whisper 服务 API

一个开源的多模态大语言模型,旨在实现实时的视觉和语音交互。
能够同时处理视频、图像、文本和音频数据,通过减少交互延迟、增强语音处理能力和改进多模态理解,达到了接近GPT-4o的水平。
顯著降低交互延遲。

可控人物影像產生旨在產生以參考影像為條件的人物影像,從而允許精確控制人物的外觀或姿勢。然而,現有方法儘管實現了較高的整體影像質量,但通常會扭曲參考影像的細粒度紋理細節。我們將這些扭曲歸因於對參考影像中相應區域的關注不夠
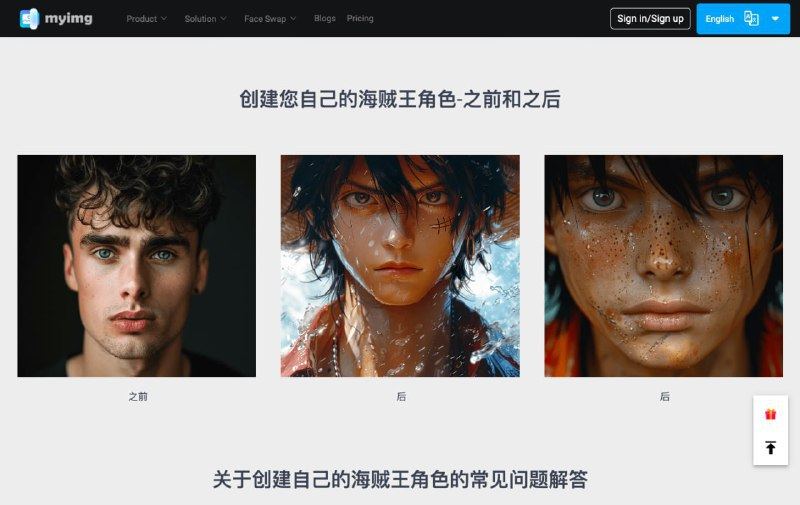
网站简介:一款可以将照片即时转换为卡通和动画艺术风格的人工智能工具。
只需上传一张照片,网站的AI技术会迅速将其转换为一个个性化的《海贼王》动漫角色。
现代计算设备功能强大且小巧,可以轻松佩戴在身体上。然而,电池成为设计和用户体验的主要障碍,增加了设备的重量和体积,并且需要定期充电和移除设备。
为了解决这些问题,卡内基梅隆大学的研究人员提出了通过人体传输能量的“皮肤供电”技术。
強大的計算設備現在足夠小,可以輕鬆佩戴在身上。然而,電池造成了主要的設計和使用者體驗障礙
Ebook2Audiobook开源项目
将电子书自动转换为有声书 支持语音克隆、多种语言
Hertz-dev:首个会话音频开源模型
小宾AI抠图
AI 头像动起来