

YOLOv8:目标检测跟踪模型
YOLOv8能够在图像或视频帧中快速准确地识别和定位多个对象,还能跟踪它们的移动,并将其分类。
除了检测对象,YOLOv8还可以区分对象的确切轮廓,进行实例分割、估计人体的姿态、帮助识别和分析医学影像中的特定模式等多种计算机视觉任务。
YOLOv8能够在图像或视频帧中快速准确地识别和定位多个对象,还能跟踪它们的移动,并将其分类。
除了检测对象,YOLOv8还可以区分对象的确切轮廓,进行实例分割、估计人体的姿态、帮助识别和分析医学影像中的特定模式等多种计算机视觉任务。

它可以根据文字描述来生成视频。但它不是基于扩散模型,而本身就是个LLM,可以理解和处理多模态信息,并将它们融合到视频生成过程中。
不仅能生成视频,还能给视频加上风格化的效果,还可修复和扩展视频,甚至从视频中生成音频。
一条龙服务…
例如,VideoPoet 可以根据文本描述生成视频,或者将一张静态图片转换成动态视频。它还能理解和生成音频,甚至是编写用于视频处理的代码。

支持上传图片和文字提示生成视频
从官网提供的演示视频来看,质量非常高,是Runway的强有力竞争者。
支持通过相机运动来控制视频的生成过程。

OpenAI在2019年8月份就推出了他们的一音乐生成模型:Jukebox
Jukebox能够根据提供的歌词、艺术家和流派信息生成多种流派和艺术家风格的完整音乐和人声歌曲。
最牛P的是,3年前的质量就已经这样了…
而且据说Jukebox 2即将发布

通过连接大语言模型与多模态适配器和扩散解码器,AnyGPT实现了对各种模态输入的理解和能够在任意模态中生成输出的能力。
也就是可以处理任何组合的模态输入(如文本、图像、视频、音频),并生成任何模态的输出…
实现了真正的多模态通信能力。
这个项目之前叫NExT-GPT
可以根据不同性别和体型自动调整,和模特非常贴合。也可以根据自己的需求和偏好调整试穿效果
OOTDiffusion支持半身模型和全身模型两种模式。

将运行在 Groq 上的 Llama-70B 模型与 Whisper 模型结合,实现了几乎零延迟的性能。
如果在GPT 4或者未来更高版本GPT 5能实现这速度,想象空间很大,几乎秒级就能写一本书出来,AI实时通话都不是问题!

能自动从视频中识别和分离出不同的声音源,并与画面位置匹配。
例如,它可以识别出视频中哪个人物正在说话或哪个乐器正在被演奏。
而且还能够分别提取和分离这些声音源的声音。
PixelPlayer能自我学习分析,无需人工标注数据。
这种能力为音视频编辑、多媒体内容制作、增强现实应用等领域提供了强大的工具,使得例如独立调整视频中不同声音源音量、去除或增强特定声音源等操作成为可能。
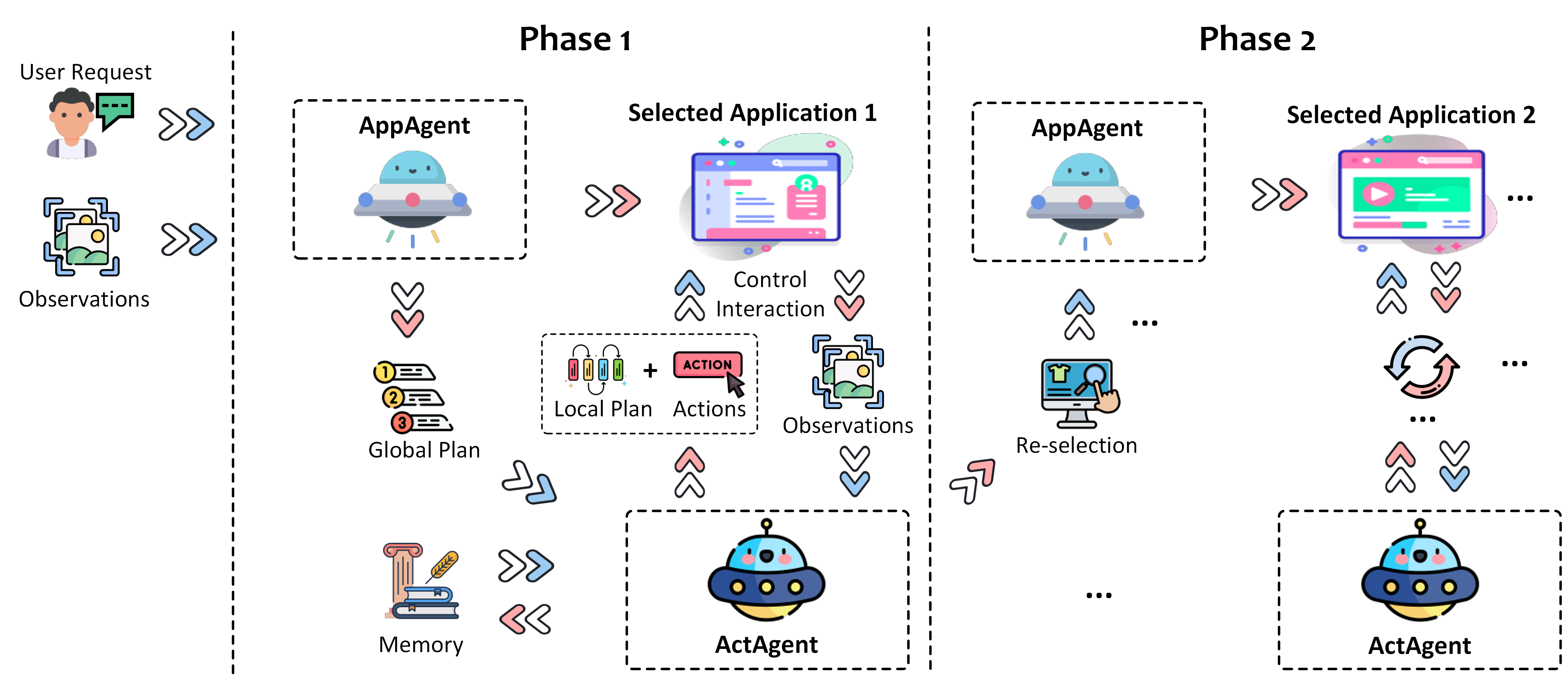
它可以通过理解用户的自然语言指令和屏幕的视觉内容,自动执行一系列复杂的任务。
比如“删除Word文档中的所有图片”或“在PowerPoint文稿中添加一个新幻灯片”。
它结合了GPT 4-V,能够理解和Windows应用程序的图形用户界面(GUI)并执行操作。
UFO能够在Windows应用程序中执行各种操作,如点击按钮、填写表单、浏览文件等,就好像一个人在使用鼠标和键盘操作电脑一样。












