

涵盖了机器学习系统的设计、构建、投产、优化、运转和维护工作。 详细的学习内容有: • 机器学习基础:涵盖机器学习的基本原理和方法。 • 特征工程:探讨如何有效地处理和转换数据,以提高模型性能。
AI news tracing site



涵盖了机器学习系统的设计、构建、投产、优化、运转和维护工作。 详细的学习内容有: • 机器学习基础:涵盖机器学习的基本原理和方法。 • 特征工程:探讨如何有效地处理和转换数据,以提高模型性能。

Synthesia 是一个基于人工智能的 AI 视频生成制作平台,利用深度学习算法来合成逼真的人脸表情和口型,从而让虚拟的人物能够根据用户输入的文字来说话。用户只需要在网页上输入文字,就可以生成一段专业、有说服力的视频。 Expressive-1能根据文本自动做出皱眉、微笑、皱眉头等表情。
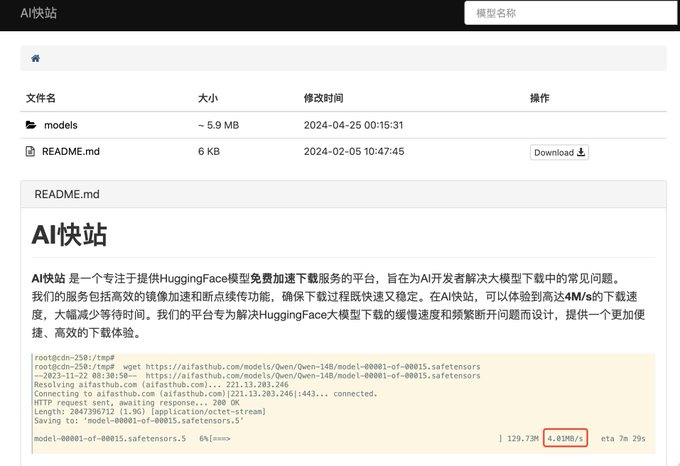
AI快站的特点: 高速下载:提供的模型下载速度相对较快,减少等待时间 模型资源丰富:涵盖大部分常用开源模型,更新速度快 支持断点续传:提供下载器,大模型下载时遇到中断也不再是问题

这款模型被视为国内首个达到Sora级别的视频模型。 Vidu 不仅能模拟真实物理世界,还具备丰富的想象力,支持多镜头生成和高时空一致性。 Vidu 模型融合了 Diffusion 与 Transformer 技术,创新性地开发了 U-ViT 架构。

Scribie 转录的在家工作机会。 将音频和视频转录为文字内容,并从各个公司获得高薪。
构建 Perplexity 样式 LLM 答案引擎:前端到后端教程 这个仓库在过去的一周里一直在流行 关于从头开始构建答案引擎的精彩介绍!

Open-Sora Colossal-AI 团队牵头的项目,目前发布了 1.1 模型,支持 2s~15s,144p 到 720p,任何宽高比文本到图像,文本到视频,图像到视频,视频到视频,无限时间生成的版本。

Amazon Q 不仅可以生成高度准确的代码,还可以进行测试、调试,并具有多步骤规划和推理功能,可以转换和实施根据开发人员请求生成的新代码。 Amazon Q...
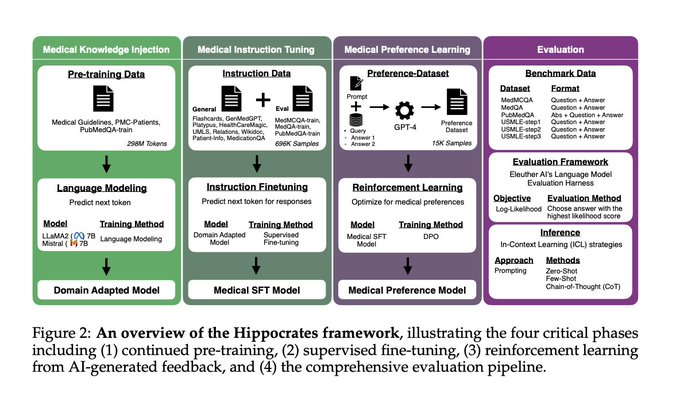
Koç 大学、Hacettepe 大学、Yıldız Technical University 和 Robert College 的研究人员推出了“Hippocrates”,这是一个专为 LLMs...
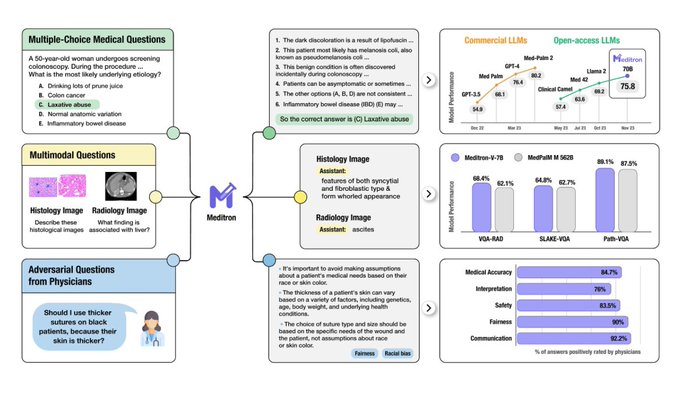
@ICepfl 和 @YaleMed 的研究人员联手构建了 Meditron,这是一款适用于资源匮乏的医疗环境的 LLM 套件。借助 Llama 3,他们的新模型在 MedQA 和 MedMCQA 等基准测试中优于其参数类别中的大多数开放模型。

在临床推理、多模态理解和长文本处理方面都有很大的提升。 研究人员用了14个医疗基准测试Med-Gemini的能力。 结果发现,它在10个基准上都取得了最佳表现,远超之前最强的GPT-4模型。
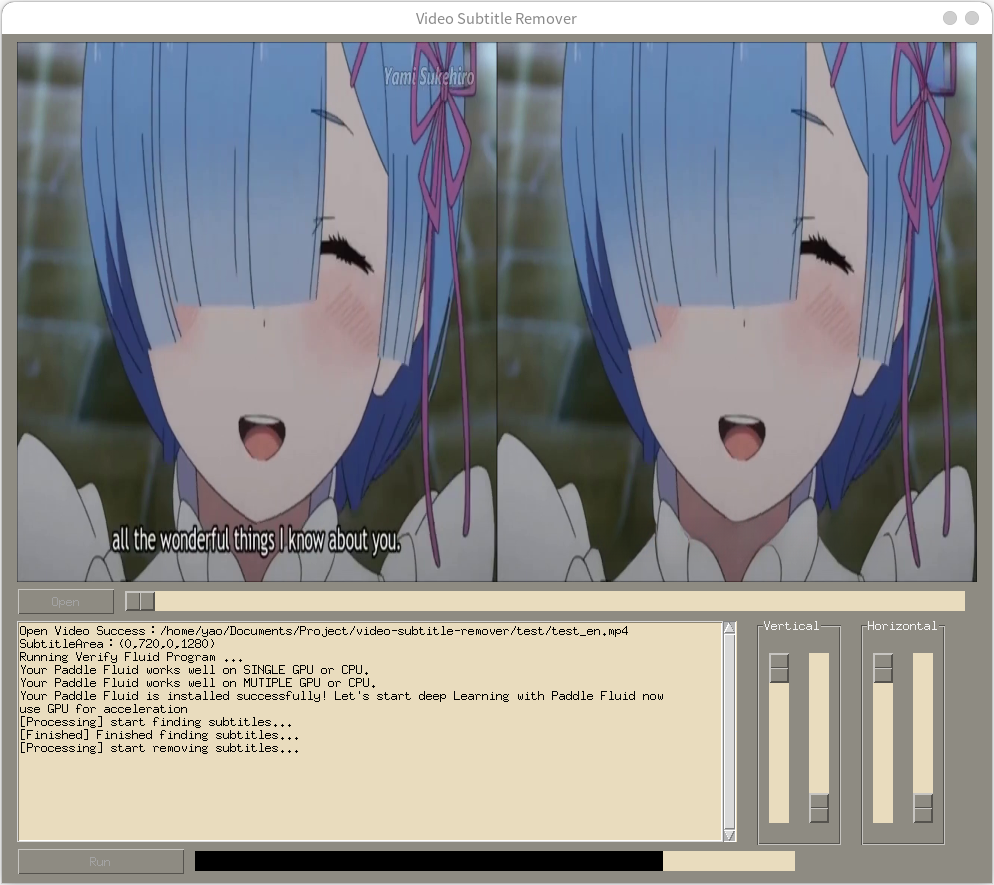
Video-subtitle-remover (VSR) 是一款基于AI技术,将视频中的硬字幕去除的软件。 主要实现了以下功能: 无损分辨率将视频中的硬字幕去除,生成去除字幕后的文件 通过超强AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除)...
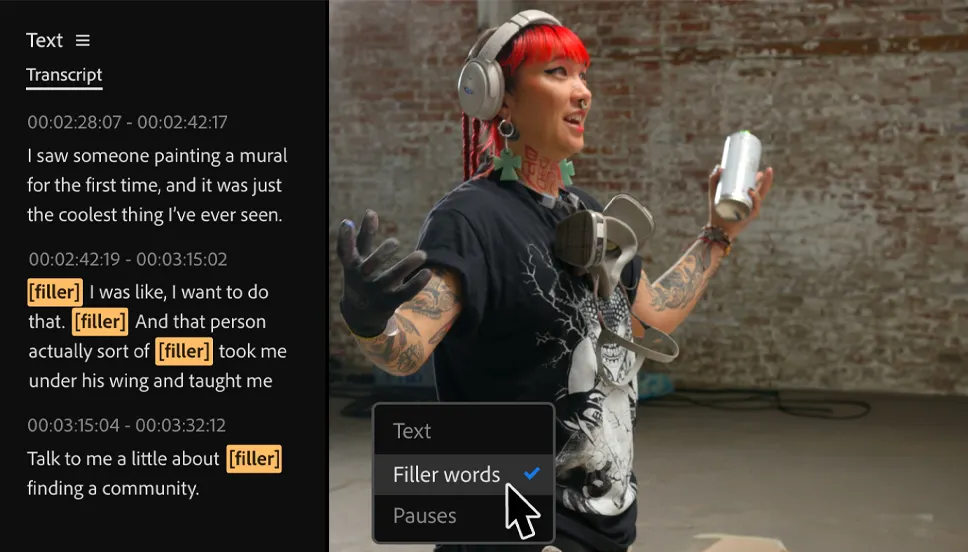
引入 AI 视频编辑和第三方Sora等AI视频模型 Adobe Premiere Pro将在今年晚些时候推出第三方AI模型,让编辑人员可以选择最适合他们素材的模型,直接在软件中生成和编辑。
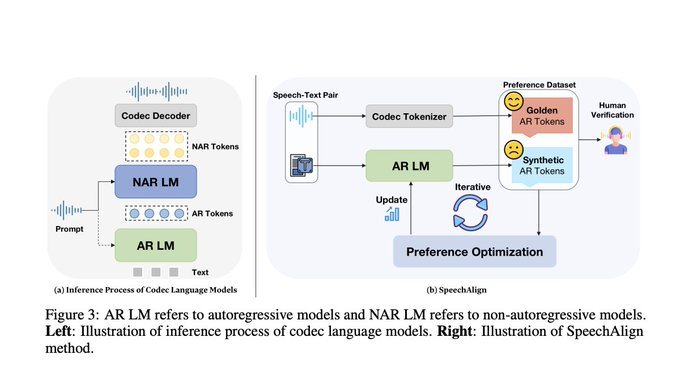
复旦大学的一个研究团队开发了 SpeechAlign,这是一个针对语音合成核心的创新框架,使生成的语音与人类偏好保持一致。与优先考虑技术准确性的传统模型不同,SpeechAlign 通过直接将人类反馈纳入语音生成而引入了巨大转变。这个反馈循环确保产生的语音在技术上是合理的并且在人类层面上产生共鸣。
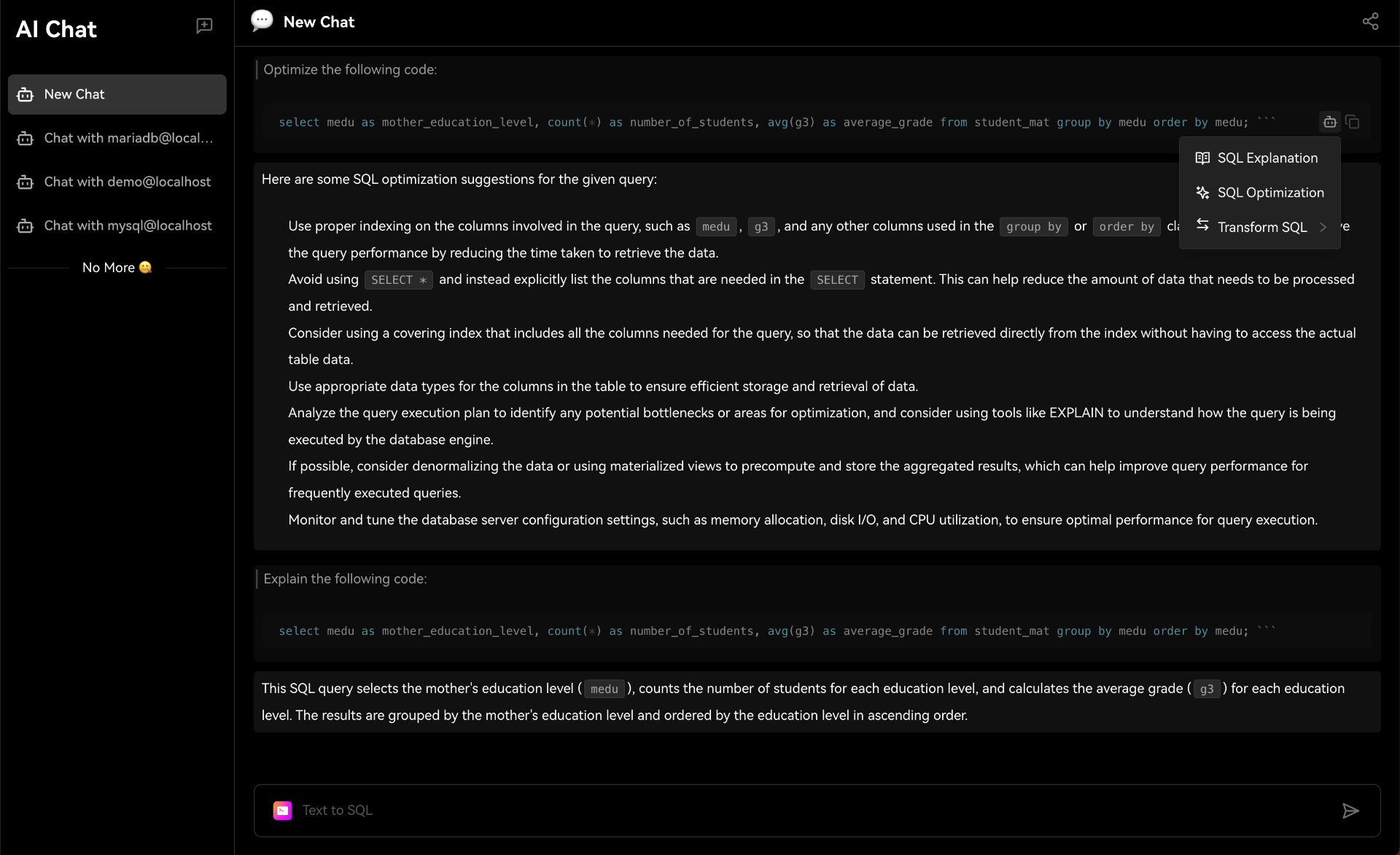
该项目已经吸引了超过100万开发者的使用,并且在 GitHub 上获得了大量的关注和支持。 Chat2DB通过人工智能技术,使得用户可以使用自然语言来处理和查询数据,无需深入了解复杂的数据库语言或编程技能。

本文研究了对物体探测器发起对抗性攻击的艺术和科学。大多数关于现实世界对抗性攻击的工作都集中在分类器上,分类器为整个图像分配整体标签,而不是定位图像内对象的检测器。检测器的工作原理是考虑图像中具有不同位置、大小和纵横比的数千个“先验”(潜在的边界框)。为了欺骗对象检测器,对抗性示例必须欺骗图像中的每个











