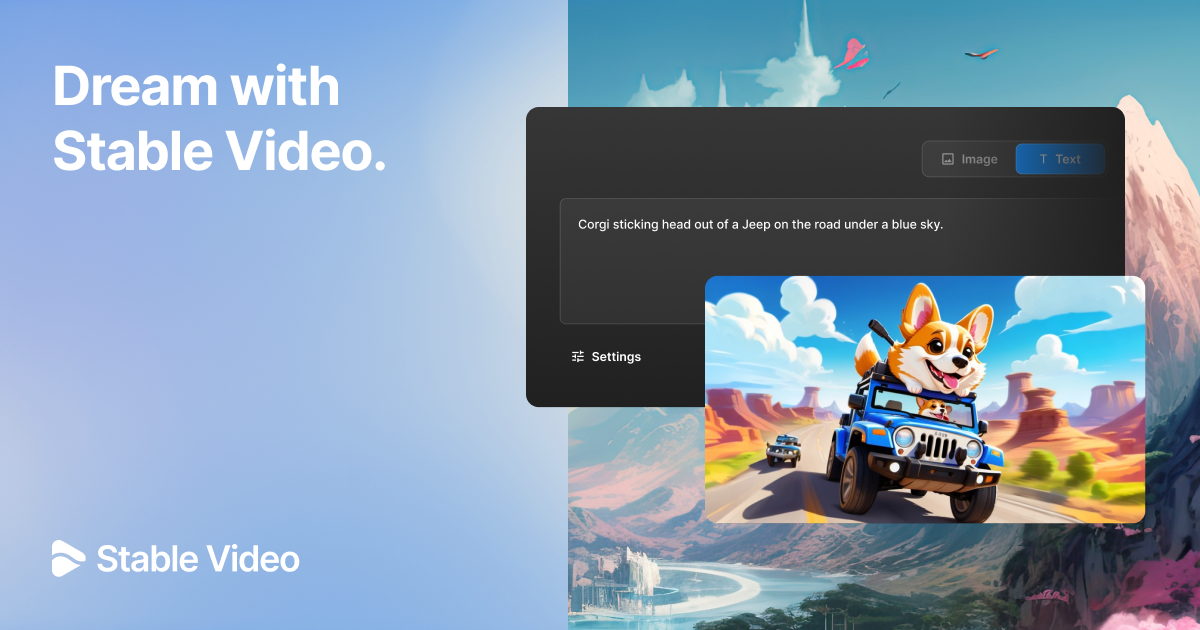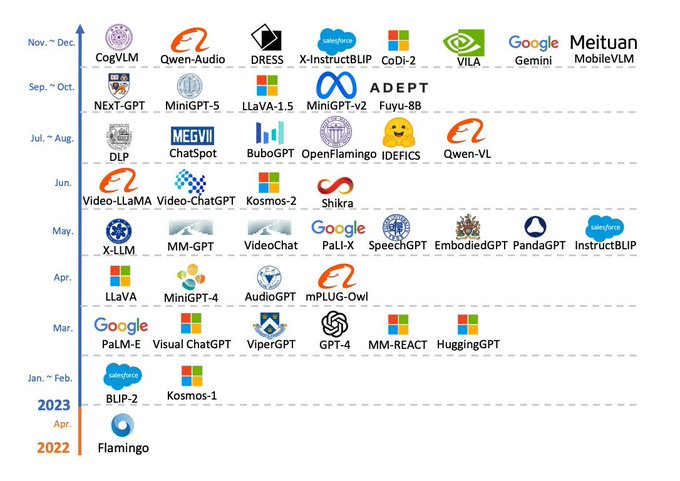
多模态 LLM 的进展
过去几周,多模态 LLMs(MM-LLMs)研究论文激增。
在这些出版物中,有一份不错的综合调查报告,总结了现有的 26 种 MM-LLMs 。

1、物体的准确放置:确保新插入的物体在视频中的位置看起来自然、合理,与视频场景的其他元素和空间布局协调一致。
2、光照和阴影的真实模拟:通过分析和模拟视频中的光照条件及其对物体的影响,生成看起来自然的阴影和光照效果,增强物体与环境的整合度。
3、风格一致性:应用风格转换技术,调整和优化视频的视觉效果,使得插入的物体在色彩、纹理等方面与背景视频保持一致,进一步提升整个视频的真实感和观感质量。

模型有1.2亿个参数,经过了10万小时的语音数据训练。
专注英语情感演讲
跨语言语音克隆
支持美国和英国声音的零样本克隆
支持长篇内容语音合成
它提供了一个拖放式的界面,允许用户轻松地创建复杂的图像处理工作流,无需编写任何代码。
你只根据需要将不同的功能块(如图像编辑功能和AI模型)组合在一起,即可实现个性化的图像自动化处理。
该工具主要解决在电商领域遇到的批量处理图片问题。
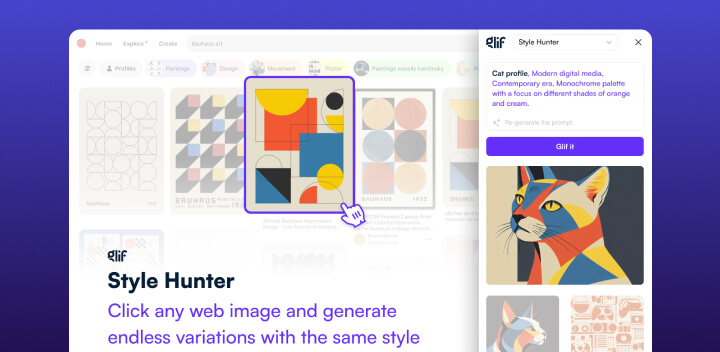
只需右键点击图像并输入你的提示词,就能将该图像风格直接应用到你想要创造的新图像上,无论是模仿那个风格,还是将其与其他风格结合创造出全新的作品。

谷歌在Bard谷歌地图和Imagen-2升级,亚马逊推出了人工智能购物助手“Rufus”
此外,亚马逊、Sam Altman、佐治亚理工学院、Meta、Arc 和 Anthropic 在人工智能方面取得了巨大进展。

在创作疯狂的动漫图像和视频
在 Midjourney V6 中测试了新的 Niji 风格,并使用 Domo AI 对其进行了动画处理。
动漫武士超级英雄和恶棍!
使用 @runwayml #AI 视频工具和 Midjourney 新发布的 Niji v6 创建。