
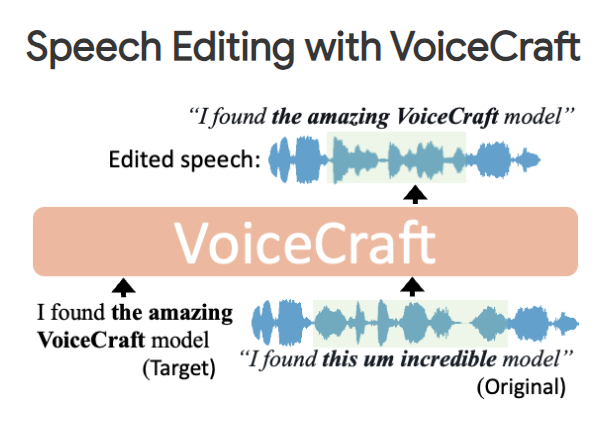
VoiceCraft:官宣超过XTTS的语音模型
支持克隆音频,支持通过修改原始音频的文本来编辑音频,演示效果非常好,看起来很有潜力。

它可以通过文本提示将数学、物理问题转换成视频内容
它会自动生成包括图表、图示、动画原理,还包含讲解内容的2分钟左右的视频。
能非常直观的帮助你了解一些知识和原理。

Google也弄了一个:一张照片+音频即可生成会说话唱歌的视频的项目
VLOGGER:基于文本和音频驱动,从单张照片生成会说话的人类视频

能够通过文字提示创造出适用于各种场景的声音和音效
如游戏中的射击和跳跃声音、动画中的雨声环境以及视频中的地铁到站声音等。
设置好语音,点击播放按钮,可以自动朗读GPT生成的内容
ChatGPT 的数据分析Data Analysis 将升级到V2 版本,功能更加强大!

它可以根据文字描述来生成视频。但它不是基于扩散模型,而本身就是个LLM,可以理解和处理多模态信息,并将它们融合到视频生成过程中。
不仅能生成视频,还能给视频加上风格化的效果,还可修复和扩展视频,甚至从视频中生成音频。
一条龙服务…
例如,VideoPoet 可以根据文本描述生成视频,或者将一张静态图片转换成动态视频。它还能理解和生成音频,甚至是编写用于视频处理的代码。
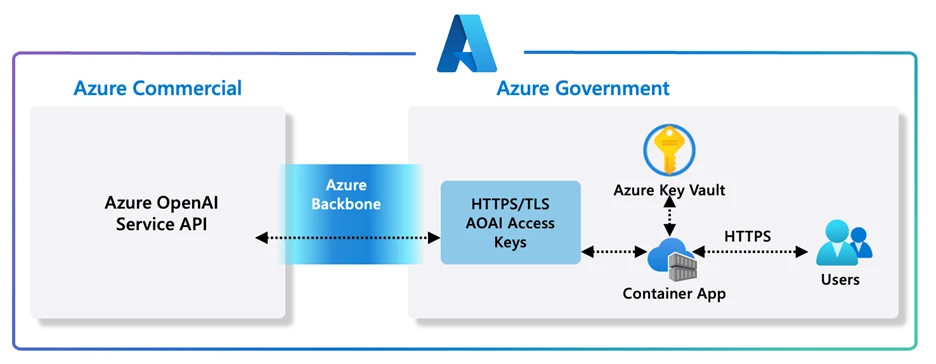
包括公开预览的Assistants API、新的文本到语音(TTS)功能、即将推出的GPT-4 Turbo和GPT-3.5 Turbo模型更新、新的嵌入模型以及微调API的更新。
与之前的聊天完成API相比,Assistants API能够记住之前的对话内容,创建持久化和无限长的线程。
Assistants API 是一项由 Azure OpenAI 提供的新服务,它旨在帮助开发者在他们的应用程序中更容易地创建高质量的人工智能助手体验。

模型有1.2亿个参数,经过了10万小时的语音数据训练。
专注英语情感演讲
跨语言语音克隆
支持美国和英国声音的零样本克隆
支持长篇内容语音合成

是通过对OpenAI的Whisper语音识别模型反向工程来实现的。
通过这种反转过程,WhisperSpeech能够接收文本输入,并利用修改后的Whisper模型生成听起来自然的语音输出。
输出的语音在发音准确性和自然度方面都非常的优秀。

可以选择角色和设定,创建独特的AI生成故事。通过AI驱动的故事和个性化练习吸引学生阅读并提高阅读流畅度。
当你阅读时,语音转文本AI分析阅读流利性,检测学习者挑战的词汇,并记录阅读的准确性、速度和时间。












