

Truecaller允许用户克隆自己的声音,来让AI接听电话
Truecaller 很自豪地宣布与 Microsoft 建立合作伙伴关系,利用 Microsoft Azure AI Speech 的全新个人语音技术。 Truecaller 的 AI 助手于 2022 年 9 月首次推出,已经融合了多种 AI 技术,可以自动为您接听电话、屏幕呼叫、接收消息、代表您回复或记录通话以供您以后查看。
Truecaller 很自豪地宣布与 Microsoft 建立合作伙伴关系,利用 Microsoft Azure AI Speech 的全新个人语音技术。 Truecaller 的 AI 助手于 2022 年 9 月首次推出,已经融合了多种 AI 技术,可以自动为您接听电话、屏幕呼叫、接收消息、代表您回复或记录通话以供您以后查看。

ChatTTS:专门为对话场景设计的文本到语音TTS模型
该模型经过超过10万小时的训练,公开版本在 HuggingFace 上提供了一个4万小时预训练的模型。
专为对话任务优化,能够支持多种说话人语音,中英文混合等。
Seed-TTS,这是一系列大规模自回归文本转语音(TTS)模型,能够生成几乎与人类语音无法区分的语音。
Seed-TTS作为语音生成的基础模型,在语音上下文学习中表现出色,在说话者相似性和自然性方面的表现与真实人类语音在客观和主观评估中相匹配。
通过微调,我们在这些指标上获得了更高的主观评分

可以将你直播说话时候的声音变声其他各种角色和性别的声音。
还能调整音调、音调动态和混响等参数,塑造个性化的声音。
也可以将你声音与任何角色的声音以任意比例混合,创造出新的声音 。
Audio Native 是一个嵌入式音频播放器,可以自动为网页内容生成语音
只需插入一段简短的代码,即可插入到任何网页和内容中,自动为内容生成语音旁白。
您现在正在阅读的这一行的上方有一个播放按钮。按播放键,您可以收听由 ElevenLabs 语音自动生成的这篇文章的旁白。我们将这种嵌入式语音播放器称为“Audio Native”。

OpenVoice,这是一种多功能的即时语音克隆方法,只需要参考说话者的一个简短的音频剪辑即可复制他们的声音并生成多种语言的语音。除了复制参考说话者的音色之外,OpenVoice 还可以对语音风格进行精细控制,包括情感、口音、节奏、停顿和语调。
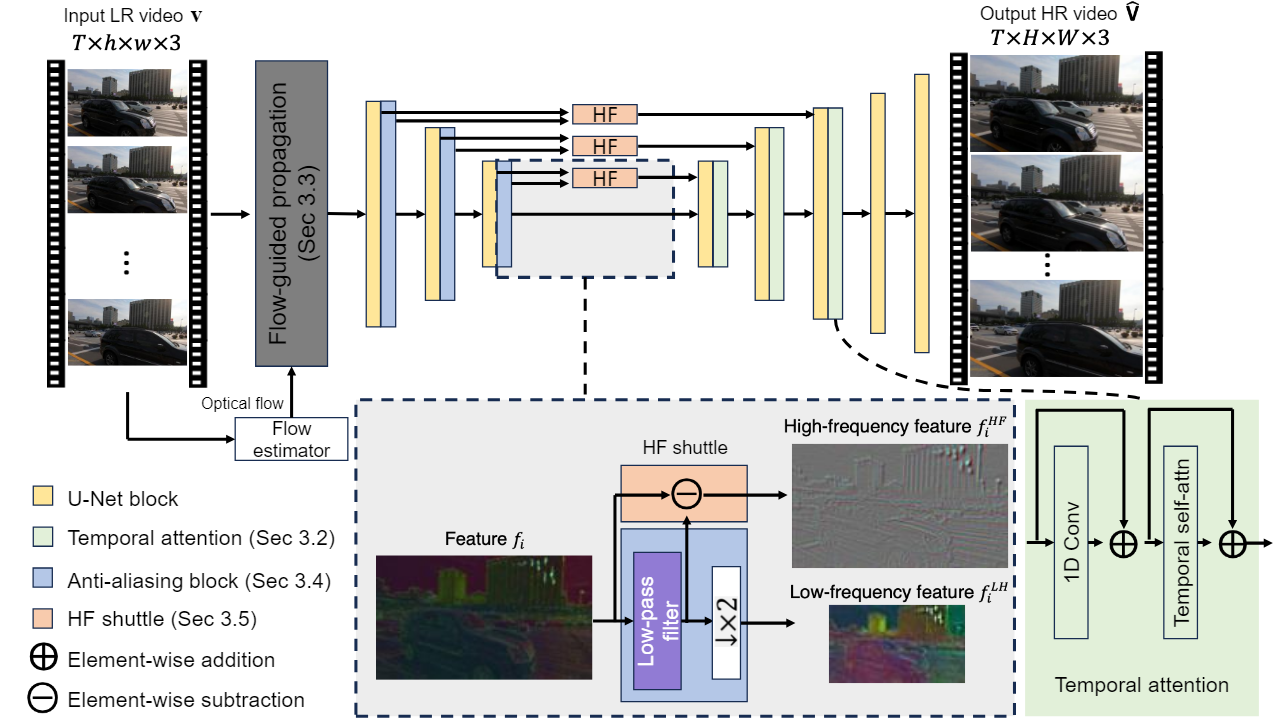
VideoGigaGAN,这是一种新的生成 VSR 模型,可以生成具有高频细节和时间一致性的视频。
VideoGigaGAN 基于大规模图像上采样器——GigaGAN。简单地通过添加时间模块将 GigaGAN 扩展到视频模型会产生严重的时间闪烁。
确定了几个关键问题,并提出了显着提高上采样视频的时间一致性的技术。

这款模型被视为国内首个达到Sora级别的视频模型。
Vidu 不仅能模拟真实物理世界,还具备丰富的想象力,支持多镜头生成和高时空一致性。
Vidu 模型融合了 Diffusion 与 Transformer 技术,创新性地开发了 U-ViT 架构。
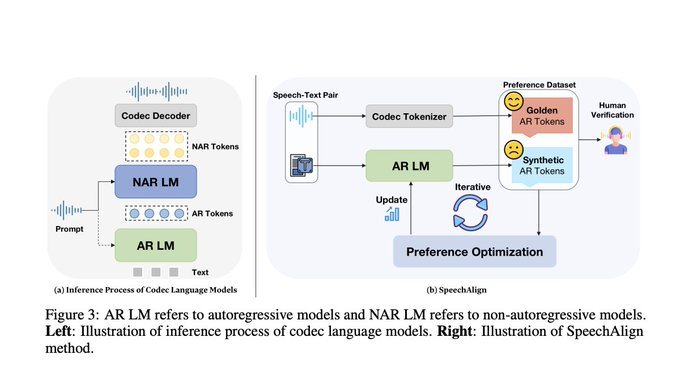
复旦大学的一个研究团队开发了 SpeechAlign,这是一个针对语音合成核心的创新框架,使生成的语音与人类偏好保持一致。与优先考虑技术准确性的传统模型不同,SpeechAlign 通过直接将人类反馈纳入语音生成而引入了巨大转变。这个反馈循环确保产生的语音在技术上是合理的并且在人类层面上产生共鸣。

开发了一套名为 MagicAdapter 的技术,通过分开处理空间和时间训练,它能从变形视频中提取更多的物理知识,并使预训练的T2V模型能够生成这类视频。
接着,引入了动态帧提取策略,这个策略特别适用于变形时光延续视频,因为这类视频变化范围广泛,涵盖了物体戏剧性的变化过程,从而包含了更丰富的物理知识。
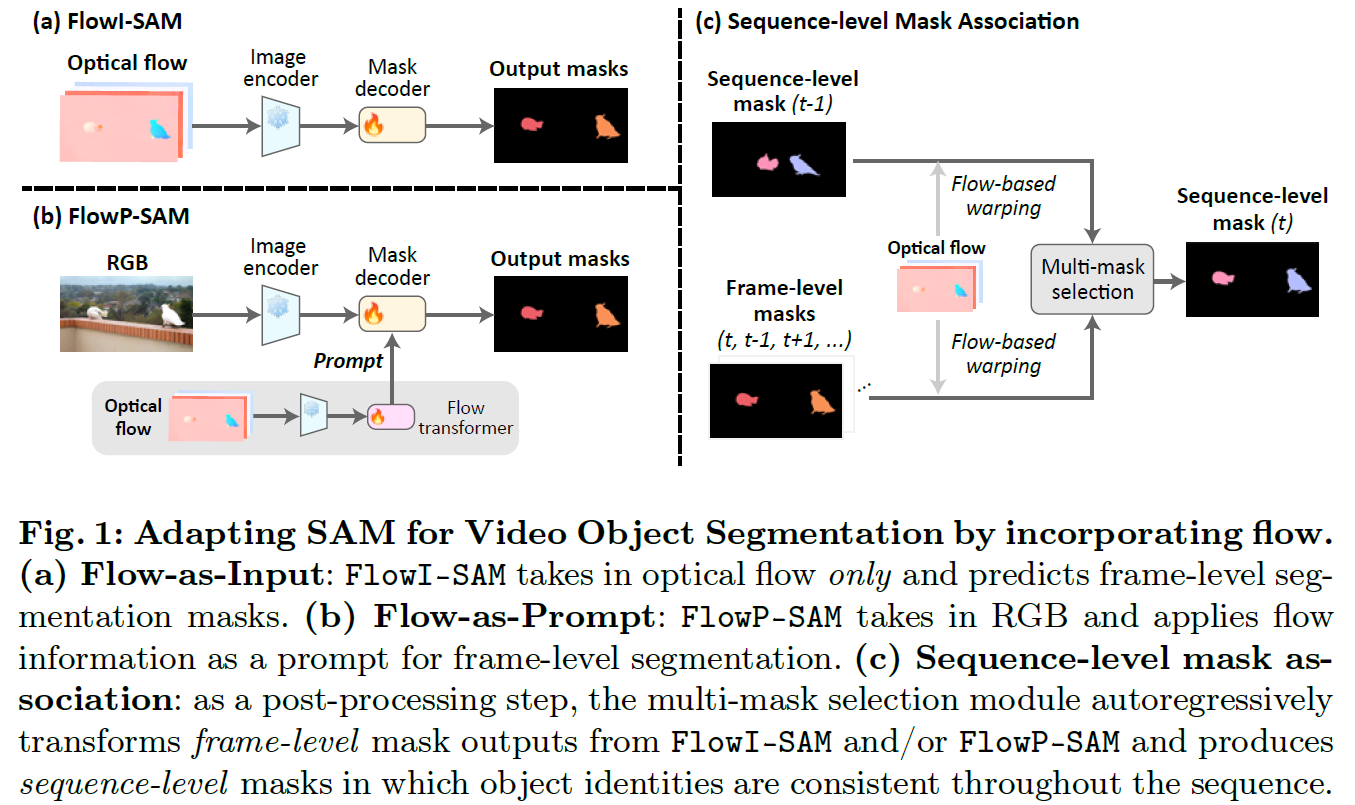
本项目的目标是运动分割——发现并分割视频中的运动对象。这是一个被广泛研究的领域,有许多仔细的、有时甚至是复杂的方法和训练方案,包括:自监督学习、从合成数据集学习、以对象为中心的表示、非模态表示等等。对本文的兴趣是确定 Segment Anything 模型 (SAM) 是否有助于完成此任务。

它支持文字、网页链接、PDF、提问等直接转视频
也就是你输入文字、链接NoLang能以视频形式快速回答。
输入PDF文件,会先给你总结内容,然后根据总结的内容在生成一个解答视频。









