Claude iOS 和 Android App 迎来新界面
新增分析工具,支持编写和运行JavaScript代码以处理和分析CSV文件数据
Anthropic 今日上线了全新的 Claude AI 内置工具,可以编写和运行 JavaScript 代码,处理数据、进行分析并生成洞察。
现代计算设备功能强大且小巧,可以轻松佩戴在身体上。然而,电池成为设计和用户体验的主要障碍,增加了设备的重量和体积,并且需要定期充电和移除设备。
为了解决这些问题,卡内基梅隆大学的研究人员提出了通过人体传输能量的“皮肤供电”技术。
強大的計算設備現在足夠小,可以輕鬆佩戴在身上。然而,電池造成了主要的設計和使用者體驗障礙
Ebook2Audiobook开源项目
将电子书自动转换为有声书 支持语音克隆、多种语言
Hertz-dev:首个会话音频开源模型
小宾AI抠图
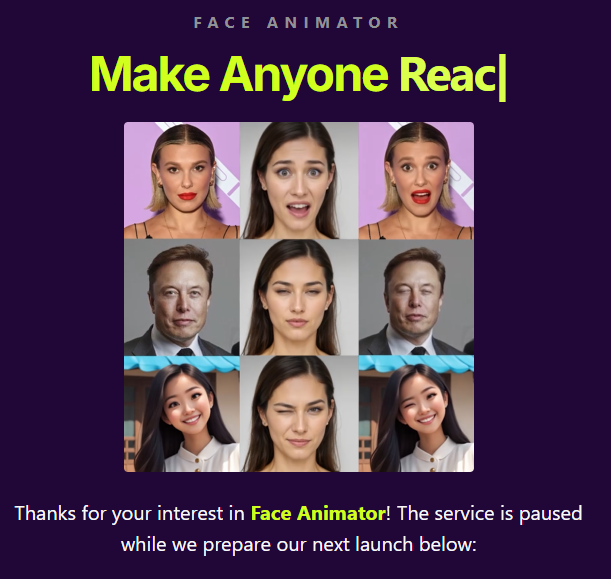
AI 头像动起来

科学家们开发了一种易于使用的软件解决方案,专门用于分析复杂的医疗健康数据。名为“ehrapy”的开源软件使研究人员能够构建和系统地检查大型异构数据集。该软件可供全球科学界使用和进一步开发。
主要开发者之一、慕尼黑亥姆霍兹计算生物学研究所和慕尼黑工业大学 (TUM) 的科学家 Lukas Heumos
AI视频剪辑
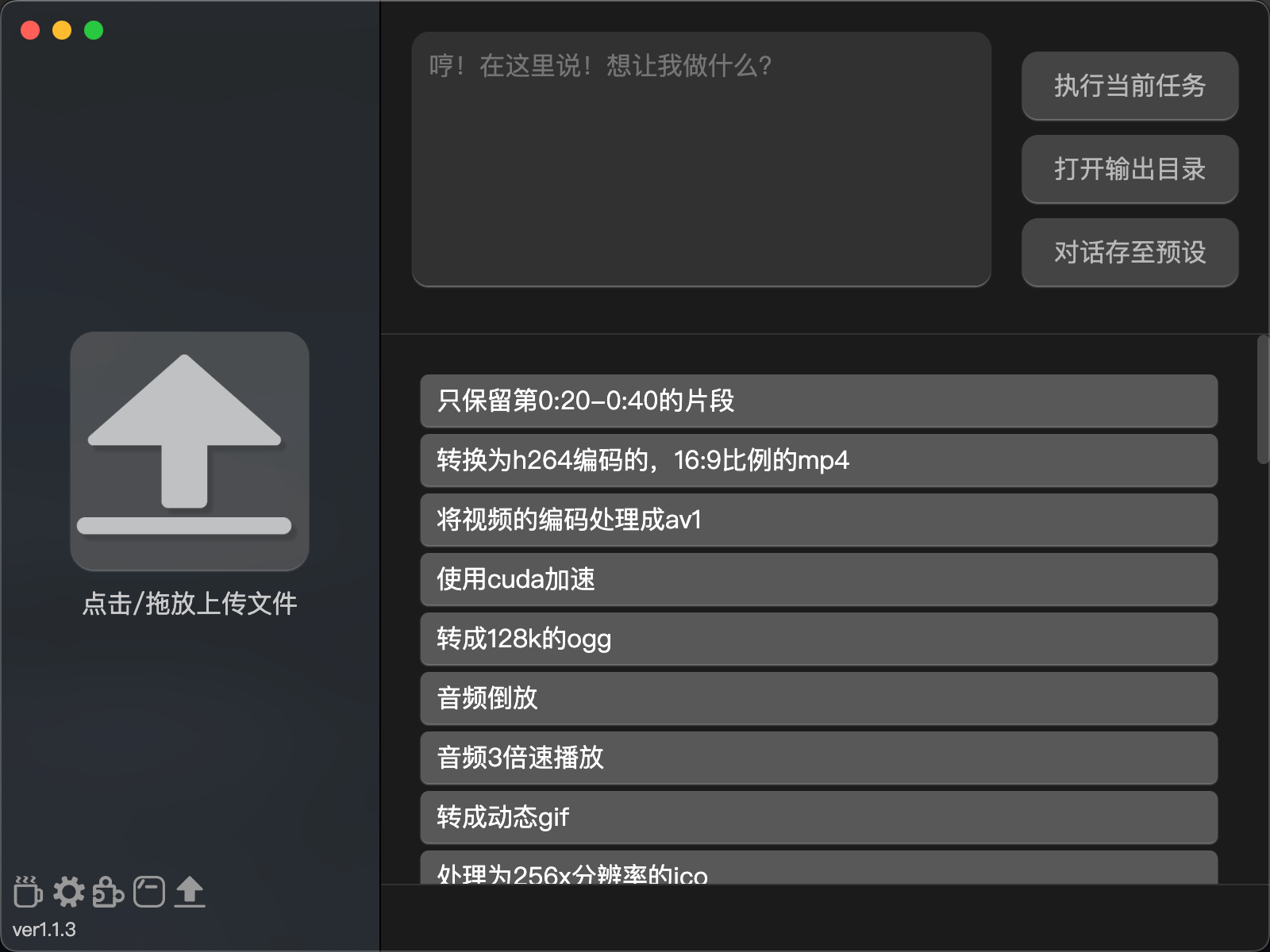
一个靠口头描述来转换文件格式的程序。
字面意思,就是口述。
例如,你拖动或者上传了一份mp4,然后你只需在输入框内描述你想干的内容。 像是“转成webm”“只保留视频第10秒到20秒之间的内容”“提取音频文件”“将视频倒放”这类。 然后点击按钮们等待进度条完成就行。 运用了ChatGPT和FFmpeg的对接。
一个开源项目,旨在代理Midjourney的Discord频道,通过API形式调用AI绘图,提供免费的绘图接口。
支持多账号配置,每个账号可设置任务队列,并提供不同的生成速度模式(RELAX、FAST、TURBO)

RoboflowSports是一个使用深度学习模型检测和识别运动员行为分析的工具。它通过检测和分割运动员和足球等对象,为体育数据分析提供了强大的工具。
它能识别并分割图像中的不同对象,例如运动员和足球,提供更精细的图像分析。通过精确的对象检测和图像分割技术,提供更高精度的体育数据分析,帮助教练和分析师更好地了解比赛情况和运动员表现。
它能够感知和表达情感,并根据上下文和人类指令提供多种风格的语音响应,如说唱、戏剧、机器人、搞笑和低语等。
超过10万小时的学术和野外收集的语音数据, 涵盖了丰富的语音场景和风格。
SpeechGPT2 是在有限资源下的技术探索,由于计算和数据资源的限制,它在语音理解的噪声鲁棒性和语音生成的音质稳定性方面仍有一些不足。