
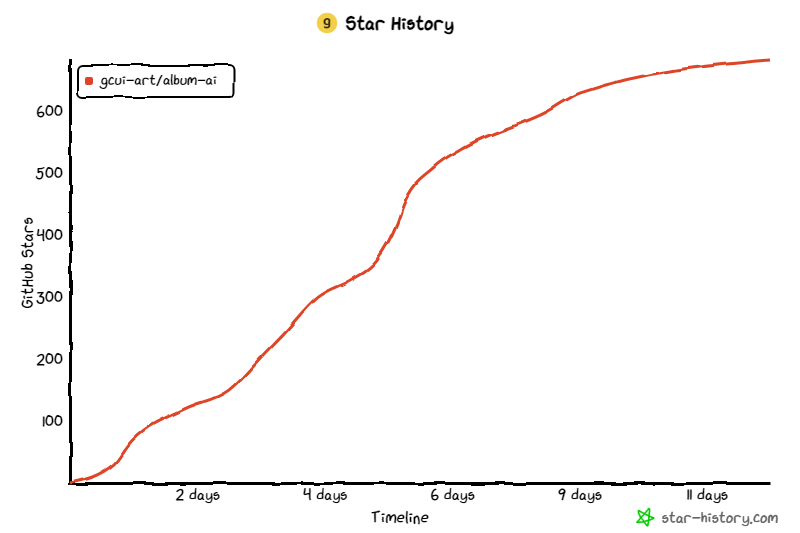
一个开源项目:AI相册
相册AI是一个实验项目,使用最近发布的gpt-4o-mini作为视觉模型,自动识别相册中图像文件的元数据。然后,它利用 RAG 技术来实现与专辑的对话。
它可以用作传统相册,也可以用作图像知识库来辅助LLM进行内容生成。
相册AI是一个实验项目,使用最近发布的gpt-4o-mini作为视觉模型,自动识别相册中图像文件的元数据。然后,它利用 RAG 技术来实现与专辑的对话。
它可以用作传统相册,也可以用作图像知识库来辅助LLM进行内容生成。
H2O.ai 凭借最新的 Danube3-4B 版本超越苹果并与微软竞争,在 10 次 HellaSwag 基准测试中实现了超过 80% 的准确率
新发布的 H2O-Danube3 现已在 Hugging Face 上全球发售。 H2O SLM 系列的最新成员包括 H2O-Danube3-4B 和 H2O-Danube3-500M 型号

LibreChat是一个免费的开源ChatGPT克隆版,用户可以在一个界面中选择使用不同的AI模型。它支持与OpenAI、Azure、Anthropic和Google等AI模型服务的集成。用户甚至可以在对话中切换AI模型,并使用DALL-E或Stable Diffusion等插件进行图像生成。
一款语音识别、语音合成、说话人识别、说话人验证等集成了多种语音处理功能的工具:sherpa-onnx
支持:语音识别(ASR,支持流式和非流式)、语音合成(TTS)、说话人识别、说话人验证、语种识别、音频标注、声音活动检测(VAD,例如silero-vad)、关键词检测等
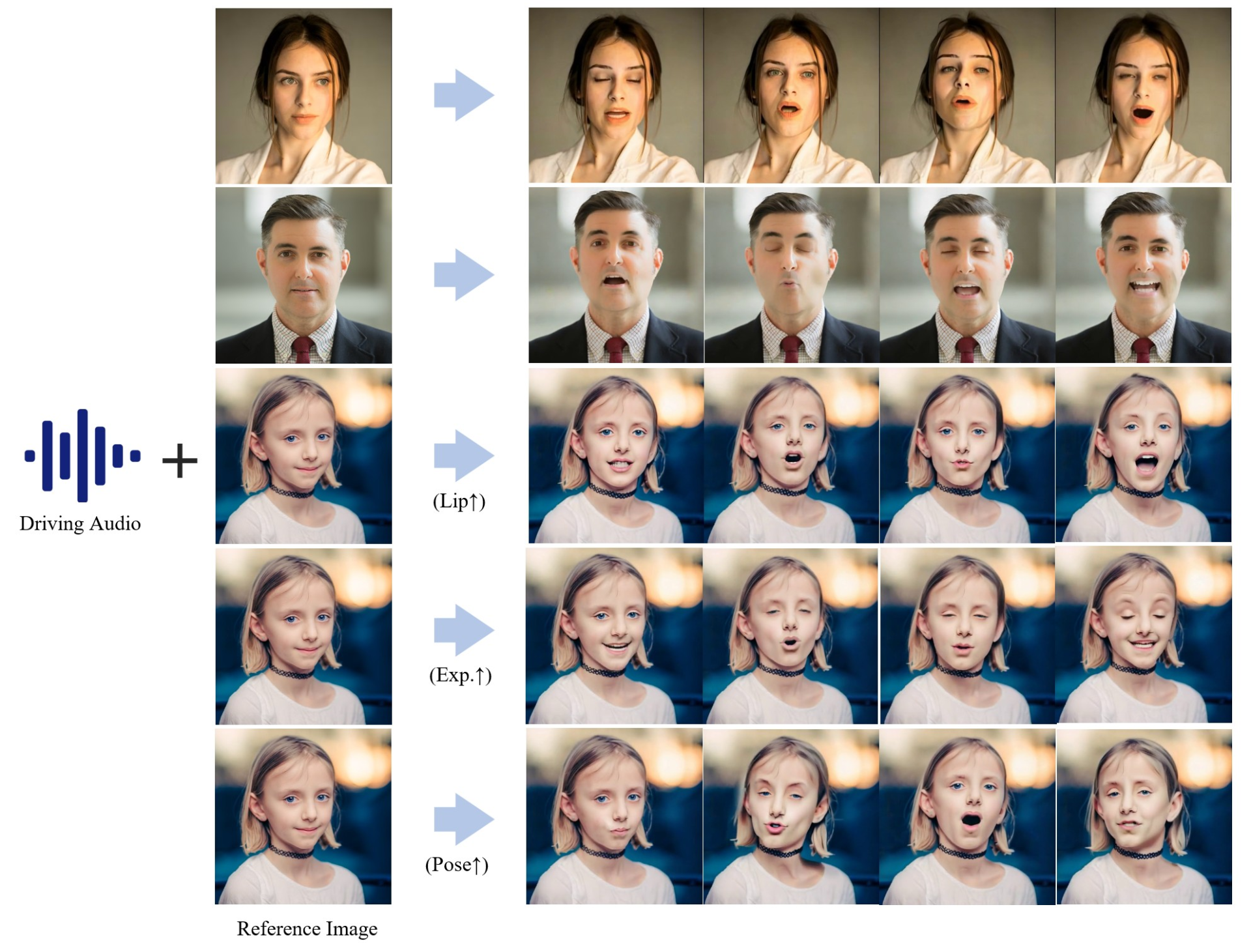
和EMO相比,该项目已开源😄
它能够通过输入语音,生成对应的人物嘴唇同步、表情变化和姿态变化的动画。
提高了语音与生成动画之间的对齐精度,使动画的嘴唇、表情和姿态与语音更匹配。
提供对角色表情、姿态和嘴唇运动的精确控制。
支持多种表情和姿态的自适应控制,增强动画的多样性和真实性。
AI Math Notes 是一个互动绘图应用程序,用户可以在画布上绘制数学方程。
绘制完方程后,应用程序会使用多模态大语言模型 (LLM) 计算结果,并在等号旁显示。
该应用程序使用 Python 编写,图形用户界面采用 Tkinter 库,图像处理使用 PIL 库。

升级到V 2版本
与之前专注于英文文本版本相比
Glyph-ByT5-v2能够支持10种不同语言的准确拼写,显著提升了多语言文本渲染的准确性和广泛性。
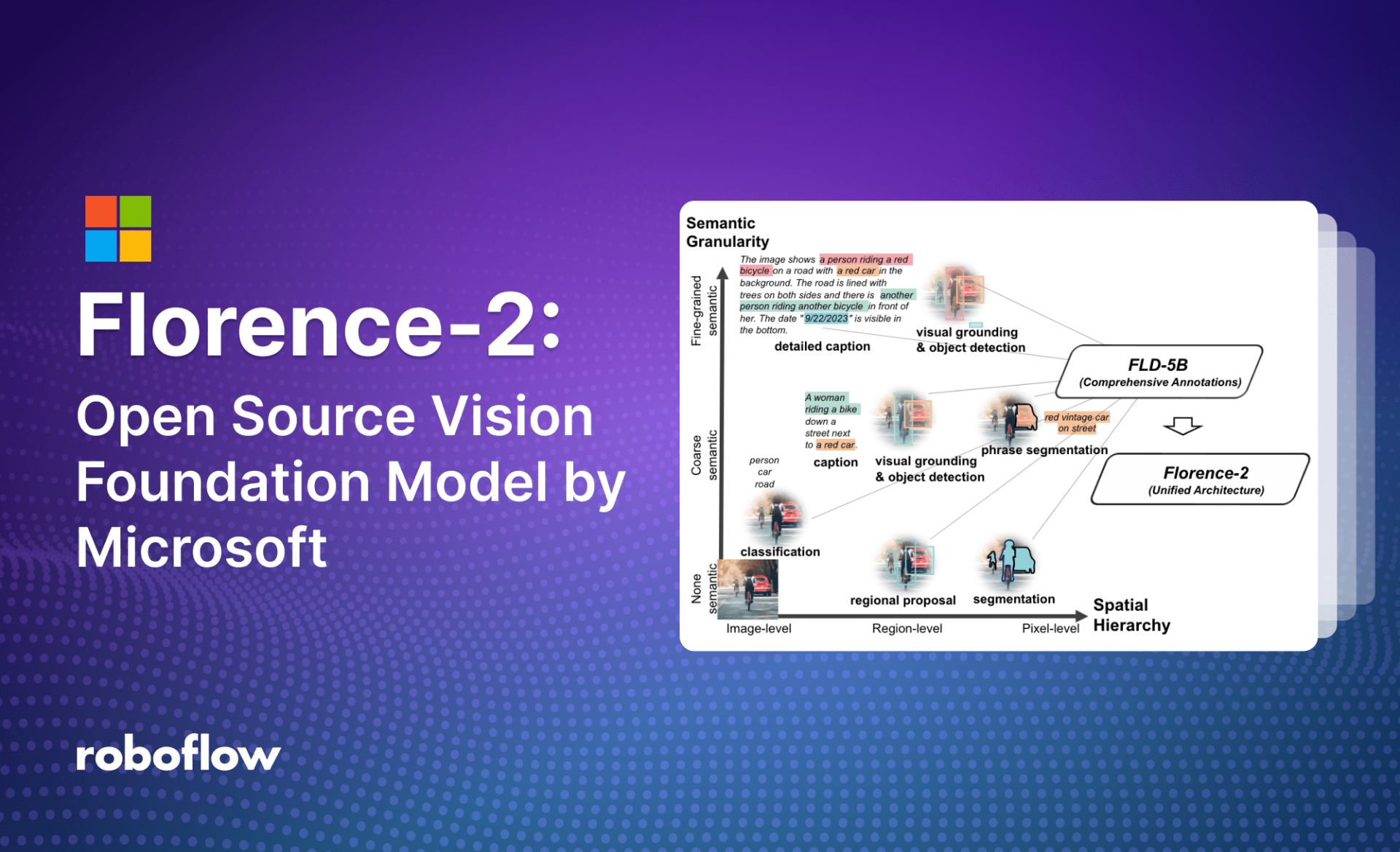
Florence-2 是 Microsoft 在 MIT 许可下开源的轻量级视觉语言模型。该模型在字幕、对象检测、接地和分割等任务中展示了强大的零样本和微调功能。
尽管尺寸很小,但它所取得的结果与大许多倍的模型(如 Kosmos-2)相当。该模型的优势不在于复杂的架构,而在于大规模的 FLD-5B 数据集,其中包含 1.26 亿张图像和 54 亿个综合视觉注释。

提供了 Colab 笔记,直接运行就可以,不需要摆弄麻烦的 Comfyui 流程和一堆模型了。
Diffutoon 能够以动漫风格渲染出细节丰富、高分辨率和长时间的视频。它还可以通过一个附加模块根据提示编辑内容。

Gen-3 Alpha是Runway的反击之作。Gen-3 Alpha的一大特点是生成的视频具有高精细度,它可以理解并生成复杂的场景和运动画面,还能胜任多种电影艺术手法。

ToonCrafter,这是一种超越传统基于通信的卡通视频插值的新方法,为生成插值铺平了道路。传统方法隐含地假设线性运动,并且没有像消遮挡这样的复杂现象,经常与卡通中常见的夸张的非线性和带有遮挡的大运动作斗争,导致插值结果难以置信甚至失败。

该框架包括一套功能齐全的高端软件分析工具,使用户能够在包括 Windows、macOS 和 Linux 在内的各种平台上分析编译的代码。功能包括反汇编、汇编、反编译、绘图和脚本编写,以及数百种其他功能。
Ghidra 支持多种处理器指令集和可执行格式,并且可以在用户交互和自动化模式下运行。用户还可以使用 Java 或 Python 开发自己的 Ghidra 扩展组件和/或脚本。









