开源项目Ghidra
该框架包括一套功能齐全的高端软件分析工具,使用户能够在包括 Windows、macOS 和 Linux 在内的各种平台上分析编译的代码。功能包括反汇编、汇编、反编译、绘图和脚本编写,以及数百种其他功能。
Ghidra 支持多种处理器指令集和可执行格式,并且可以在用户交互和自动化模式下运行。用户还可以使用 Java 或 Python 开发自己的 Ghidra 扩展组件和/或脚本。
该框架包括一套功能齐全的高端软件分析工具,使用户能够在包括 Windows、macOS 和 Linux 在内的各种平台上分析编译的代码。功能包括反汇编、汇编、反编译、绘图和脚本编写,以及数百种其他功能。
Ghidra 支持多种处理器指令集和可执行格式,并且可以在用户交互和自动化模式下运行。用户还可以使用 Java 或 Python 开发自己的 Ghidra 扩展组件和/或脚本。
PictoGraphic 是一个AI生成的插图库,提供超过40000张图像和SVG文件,你在这里可以找到适合自己的免费插图
作为设计师,通常会发现自己的设计需要 10 – 15 个高质量图形。
然而,找到这么多既能表达我们的想法又具有共同艺术风格的插图是非常具有挑战性和耗时的。通常,我们最终会花费大量时间在不同的网站和集合中寻找类似的插图,甚至花费更多的时间“再尝试一次”来编辑插图以使其适合。

Prettygraph 是一个基于 Python 的 Web 应用程序,由 @yoheinakajima 开发,用于演示文本到知识图生成的
新 UI 模式。该项目是一个快速破解项目,并不是要成为一个强大的框架,而是一个简单的 UI 想法,用于在生成知识图时动态突出显示文本输入。

能够应对各种类型的线条艺术作品,无论是手绘草图、不同的 ControlNet 线预处理工具,还是由模型生成的轮廓,都能高精确性和稳定地处理。
一个重要特点是其泛化能力极强,无需针对不同的线预处理工具更换不同的 ControlNet 模型。

支持文字生成模型、图片生成模型,分辨率512×512,5秒内即可生成。
3D内容创作在质量和速度方面都取得了显着进步。尽管当前的前馈模型可以在几秒钟内生成 3D 对象,但其分辨率受到训练期间所需的密集计算的限制。在本文中,介绍了大型多视图高斯模型 (LGM),这是一种新颖的框架,旨在从文本提示或单视图图像生成高分辨率 3D 模型。

PhysDreamer:由多所大学(包括麻省理工学院、斯坦福大学、哥伦比亚大学和康奈尔大学)合作开发。
真实的对象交互对于创建沉浸式虚拟体验至关重要,但合成真实的 3D 对象动态以响应新颖的交互仍然是一项重大挑战。与无条件或文本条件动力学生成不同,动作条件动力学需要感知对象的物理材料属性,并将 3D 运动预测建立在这些属性(例如对象刚度)的基础上。

OpenVoice,这是一种多功能的即时语音克隆方法,只需要参考说话者的一个简短的音频剪辑即可复制他们的声音并生成多种语言的语音。除了复制参考说话者的音色之外,OpenVoice 还可以对语音风格进行精细控制,包括情感、口音、节奏、停顿和语调。

Open-Sora
Colossal-AI 团队牵头的项目,目前发布了 1.1 模型,支持 2s~15s,144p 到 720p,任何宽高比文本到图像,文本到视频,图像到视频,视频到视频,无限时间生成的版本。
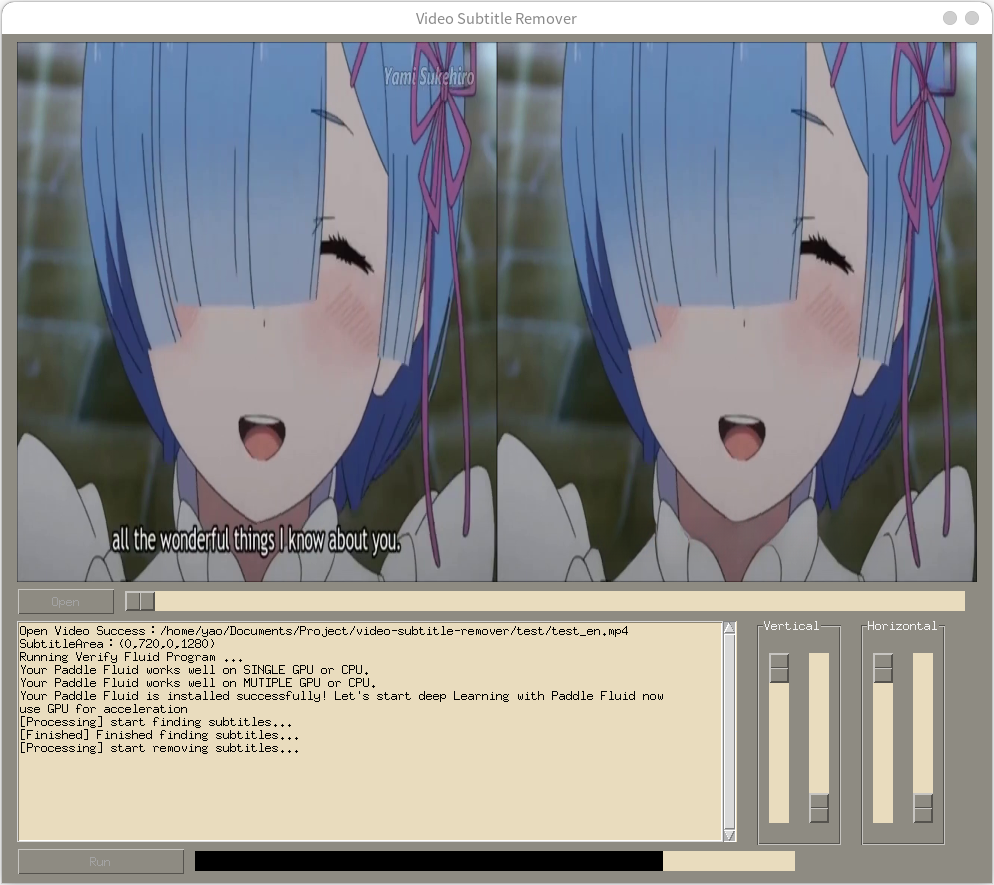
Video-subtitle-remover (VSR) 是一款基于AI技术,将视频中的硬字幕去除的软件。 主要实现了以下功能:
无损分辨率将视频中的硬字幕去除,生成去除字幕后的文件
通过超强AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除)
支持自定义字幕位置,仅去除定义位置中的字幕(传入位置)
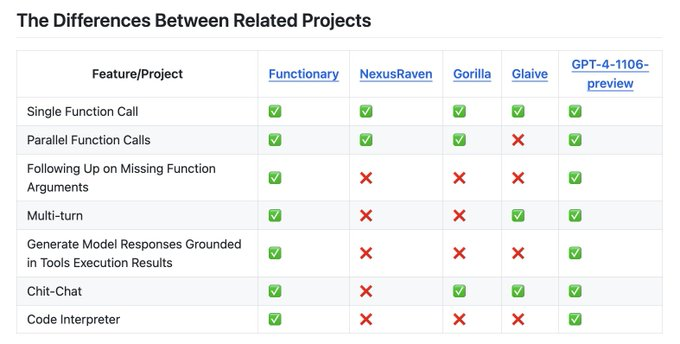
Functionary 是一种可以解释和执行函数/插件的语言模型。
该模型确定何时执行函数,无论是并行还是串行,并且可以理解它们的输出。它仅根据需要触发功能。函数定义以 JSON 架构对象的形式给出,类似于 OpenAI GPT 函数调用。

统一 Bedrock、Azure、OpenAI、Cohere、Anthropic、Ollama、Sagemaker、HuggingFace、Replicate 等 100 多种 LLM 的 API 输入输出、异常处理和负载均衡等操作的开源项目