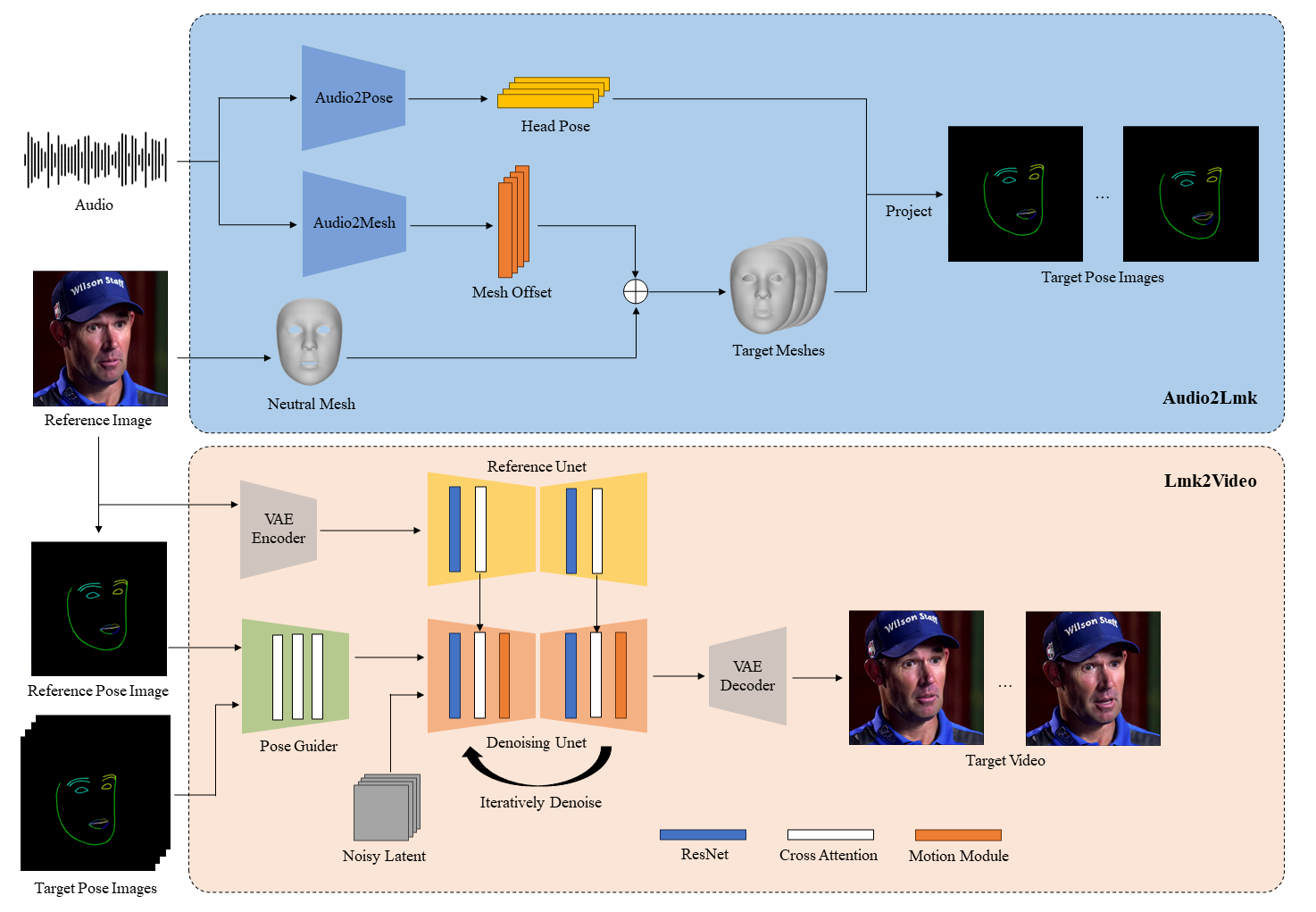
腾讯也搞了一个让照片能唱歌说话的项目
比阿里EMO先开源
AniPortrait:根据音频和图像输入 生成会说话、唱歌的动态视频
它可以根据音频(比如说话声)和一张静态的人脸图片,自动生成逼真的人脸动画,并保持口型一致。
比阿里EMO先开源
AniPortrait:根据音频和图像输入 生成会说话、唱歌的动态视频
它可以根据音频(比如说话声)和一张静态的人脸图片,自动生成逼真的人脸动画,并保持口型一致。

现在,您可以在不安装任何东西的情况下尝试 LaVague,并根据自然语言指令实现自动化 Web 操作。
这个当中最好的部分?所有堆栈都是开源的!我们使用 Hugging Face #Gradio 作为 UI,他们的 Inference API 调用 #Mixtral 、 @llama_index 用于 #RAG ,LaVague 本身也是开放的-来源。
它在语言理解、编程、数学和逻辑方面轻松击败了开源模型,如 LLaMA2-70B、Mixtral 和 Grok-1。
DBRX 在大多数基准测试中超过了 GPT-3.5。
DBRX 是基于 MegaBlocks 研究和开源项目构建的专家混合模型(MoE),使得该模型在每秒处理的标记数量方面非常快速。

最新研究更新:提供每月最佳生成式AI论文列表,包括各项研究的摘要和主题。
免费课程列表:超过65个与生成式AI相关的免费课程。
面试资源:面试准备材料,特别是针对生成式AI领域的面试问题。
课程材料:《Applied LLMs Mastery 2024》课程材料。

它支持文字、网页链接、PDF、提问等直接转视频
也就是你输入文字、链接NoLang能以视频形式快速回答。
输入PDF文件,会先给你总结内容,然后根据总结的内容在生成一个解答视频。
网站: https://caizhongang.com/projects/SMPLer-X/
GitHub 存储库: https://github.com/caizhongang/SMPLer-X

例如打开/关闭抽屉、开合电脑等。DragAPart 可以预测对象组件的交互,下图为我实测结果
这项研究的目标是迈向通用运动模型而非针对特定运动结构或对象类别的模型

Alexander Reben 这十年来致力于创作艺术作品,这些作品探讨了人工智能(AI)中人性的幽默与荒谬。
他通过手工将 AI 生成的图像转换成三维模型,并将这些模型具象化于现实世界中,创造出一系列雕塑作品。